 Ben
Ben 
Continuing where we left off last week, let’s get into some BIG topics. We’re going to be large and in charge. This will be no small task.
And so on…
The Embiggening
So what is large?
Well, it’s kind of unclear. Large mainly refers to the number of parameters in a model. Parameters, simply, are the values learned by the model through viewing data. Data is the other “large” part of LLMs. GPT-3 is 175 billion parameters, trained on 753 billion GB worth of text. GPT-4 is rumored to have 1.8 trillion parameters. Compare that to BERT, which has 345 million parameters. So we’re talking LARGE.
But why is large?
There’s a concept that’s been around since around 2008 called “zero-shot” learning. Essentially, it means that a model can give an answer to a question without ever having been explicitly trained to do so. The simple example is that you can ask even a “small” LLM what the capital of France is, and it’ll say “Paris”.
How is this possible?
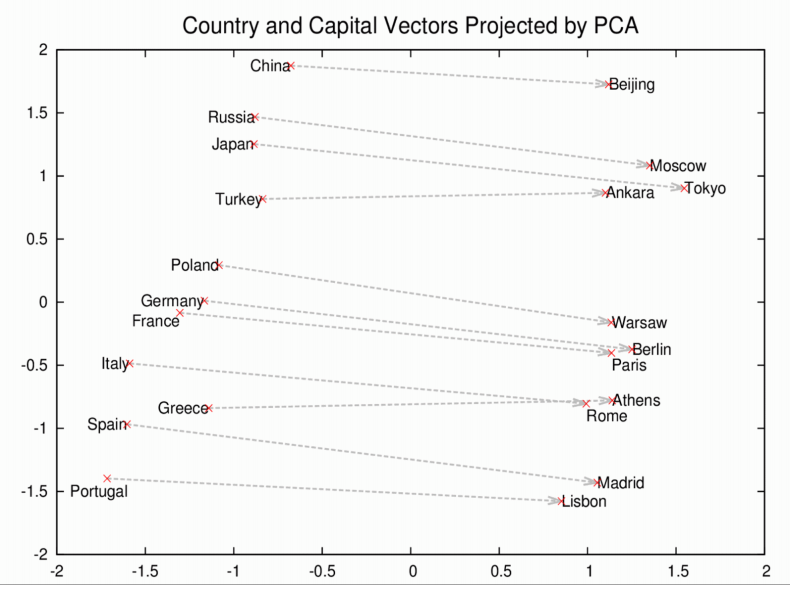
Well, think back what I described about word2vec in the last post, these models create “representations” of each word. If you decompose these representations in two dimensional space:
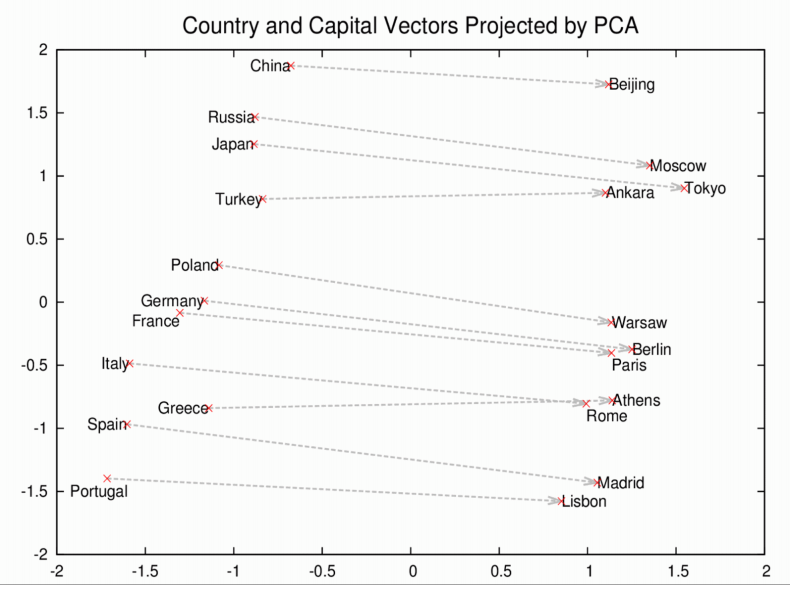
You’ll notice that all the capitols are roughly similar distance from their countries. You might even be able to extract a country-capitol vector that would translate a country into its capital. (In real life, it’s not so simple).
Remember, this all comes from the model reading enough text. It’s not explicitly trained to represent countries and their capitals in this way. One word to describe this is an “emergent” property.
LLMs go one level deeper in that they appear to be able to “understand” the relationship between countries and capitals (think of that “country-capital” vector). I use “understand” in quotes because it’s still a bit of a mystery what these models actually “understand”. But it is the case that, without explicitly being trained to answer the question, the LLM provides the correct response to “What is the capital of France?”.
A note here - I’m calling this zero-shot learning, but it may be better called “in-context learning”. The main difference is that zero shot learning may actually involve some amount of model training. For me, that’s the main difference. The input prompts may be the same, but in-context learning does not change the model.
Prompts, you say? Why, isn’t that the radical new job everyone’s talking about?
Right you are - LLMs can do much more than tell you about France. You just have to:
Say the magic word
One fascinating thing about these LLMs is that their behavior can be drastically changed based on the input. This is related to the zero-shot/in-context learning example above. The model’s representation of each word of the prompt is contingent on the other words. So if you change the context, even a little bit, you’ll change the representation across the sequence.
What does this look like? I thought this is an interesting example with ChatGPT. Here I provide a conversation, without context. One person is speaking English and I want B to give responses as if they were a French Yoda because I’m the internet and I want what I want.
![]()
ChatGPT is impressive in that without any additional information, it understands that B is repeating A, but in French. However, it doesn’t feel like talking like French Yoda. That is, unless I ask nicely:
![]()
Congrats, ya’ll are now prompt engineers. Now let it do your math homework for you:

Uh-oh. Now math is notoriously difficult for LLMs. But this is a pretty simple logic puzzle. Maybe there’s some way to break down the problem?
Now show your work
Another pretty incredible “emergent property” of LLMs is that they can show their work. If you’ve used ChatGPT, you’ll see it’s pretty chatty and impressed with itself:
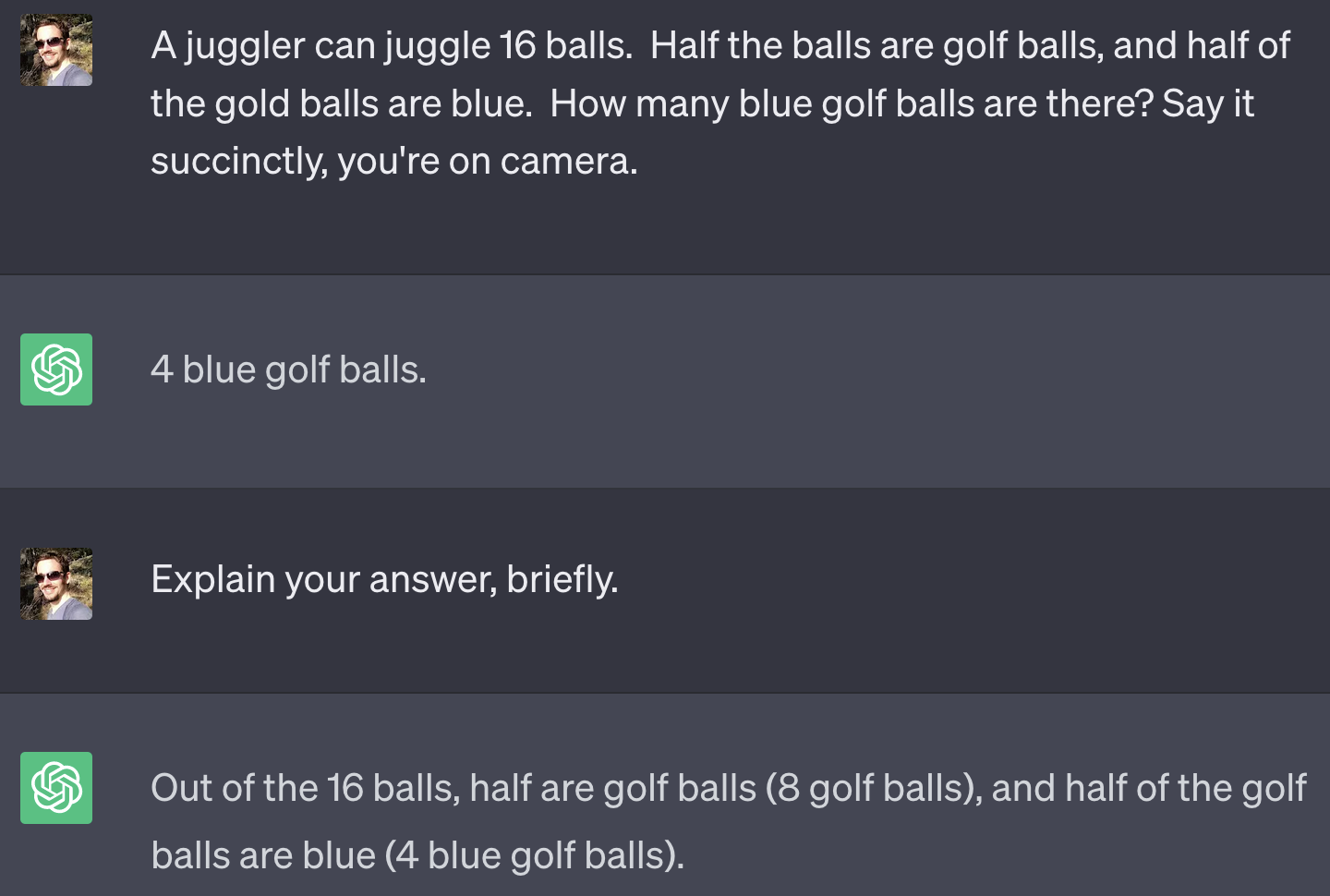
I asked it to be succinct here, but if you ask it this question it will automatically describe its “thought” process. An interesting finding detailed in Kojima et. al (2023) is that just by asking the model to work through its answer step by step, it can do better on some logic puzzles. Theirs is the example above, here’s the result when they ask the model to think step by step:

You can see with the few-shot framing, the model is given an example of how to respond and it answers the question correctly. When just ASKED to think step by step, it also responds correctly.
This is called Chain-of-Thought (CoT) prompting and is an area of active investigation. It’s another emergent property, particularly in large LLMs, usually more than 100 billion parameters.
It’s not clear why this works and, in some cases, either the explanation or the answer or both are wrong.
The term “emergent property”, in my opinion, kind of obfuscates the fact that we’re still trying to figure out exactly how this happens. In some ways, it is kind of “magic”. Autocomplete somehow turns into useful assistants, it just needs to be big enough and asked politely enough.
Or does it? Something I feel is missing from a lot of the simplifications in the media is that ChatGPT is not just autocomplete. It’s fit to purpose as an AI assistant. And you don’t become helpful by reading enough Wikipedia. Just look at any Wikipedia article discussion, if you don’t believe me.
In the next installment, I’ll talk about how, like any instrument, these models need a lot of tuning to be useful.
So tune in. Fine-tune, that is.
Sorry, will come up with a better pun by the time the next post is out.
 The Embiggening of NLP - Part 1 - Language Models
The Embiggening of NLP - Part 1 - Language Models
{kind=link}