 Ben
Ben 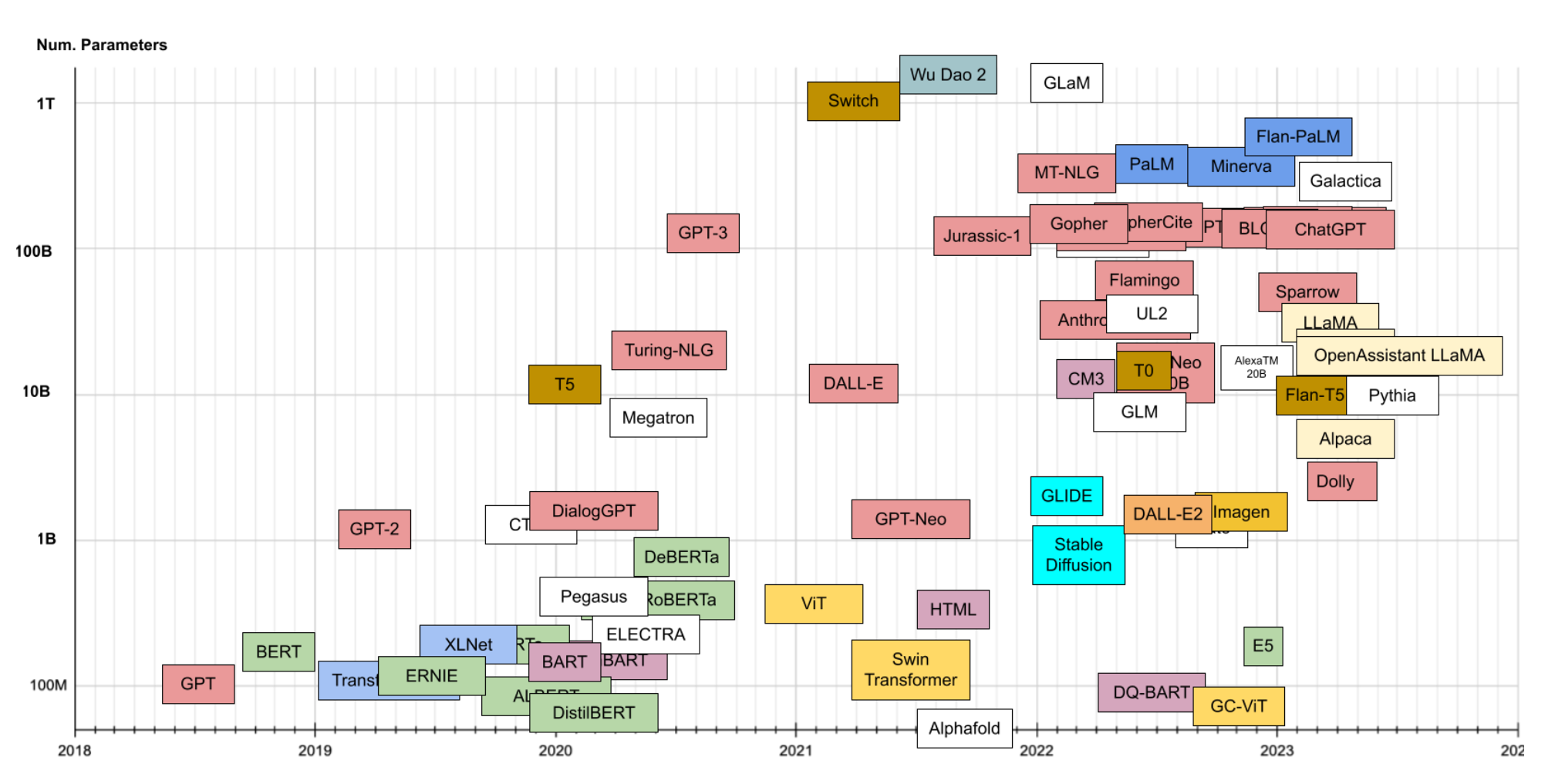
I’m not sure if you’ve heard, but there’s a new kid on the NLP block.
I guess new kid same as the old kid; OpenAI’s been in this game for a while. Though the reasons for that seem to have changed. But that’s neither here nor there.
And while ChatGPT is heralded by some as the coming of sentient machines and downplayed by others as a bulls*** engine, the fact remains it has absolutely upended the Natural Language Processing field.
In the past few months, we’ve seen an insane proliferation of what are called Large Language Models (LLMs). Check out this graphic:
 On the vertical axis, number of parameters. Colors describe Transformer family source
On the vertical axis, number of parameters. Colors describe Transformer family source
This isn’t even comprehensive, but you see the massive expansion in these models.
Generally, it’s been really tough for me to keep up with all the advances. Which speaks to how excited people are (or how slow a reader I am!). I thought that maybe other folks might be feeling the same way. For them, and myself, I decided I’d start educating myself about these models, how they’re built, how they’re used and how they can go wrong.
And no, I don’t mean wrong as in a SkyNet scenario. (Though I’ve heard differently from authorities on the subject)
Let’s start off simple.
What is a Language Model
A language model, simply put, is a system that is designed around predicting a word from context. I’ve heard some people refer to the autocomplete on your texts as an example, which I think makes sense.
So if you’re asking a friend:
“What are you doing __”
You, as a sophisticated language model, would fill the blank with “tonight” or “today”. You’d be less likely to fill it with “yesterday” or “puppy” (unless you’ve got some interesting pet names). You could imagine yourself assigning a probability of each word. That’s essentially what these language models do, try to determine the next word based on what they “know” about language.
“Know” in quotes because knowledge is a tricky thing to describe. A simple version of a language model may just be based on how often a word appears. For example, if you just had a count of how often all words appear in a corpus, you could create a probability vector across that vocabulary. Viola, you have a language model. To be fair, it’s a language model that would just predict “the” all the time, but it “knows” what it “knows”.
Reasonably, we might expect a model that incorporates other information than just raw frequency to do better. This can get increasingly complex, leading to architectures that “learn” representations that enable the model to reliably predict the next word. That’s (at the highest level) what ChatGPT is.
So why do we care about auto-complete? I barely even use it on my phone. Well the cool thing that seems to “emerge” from these methods is that by learning these representations, the models appear to have internalized language patterns more generally.
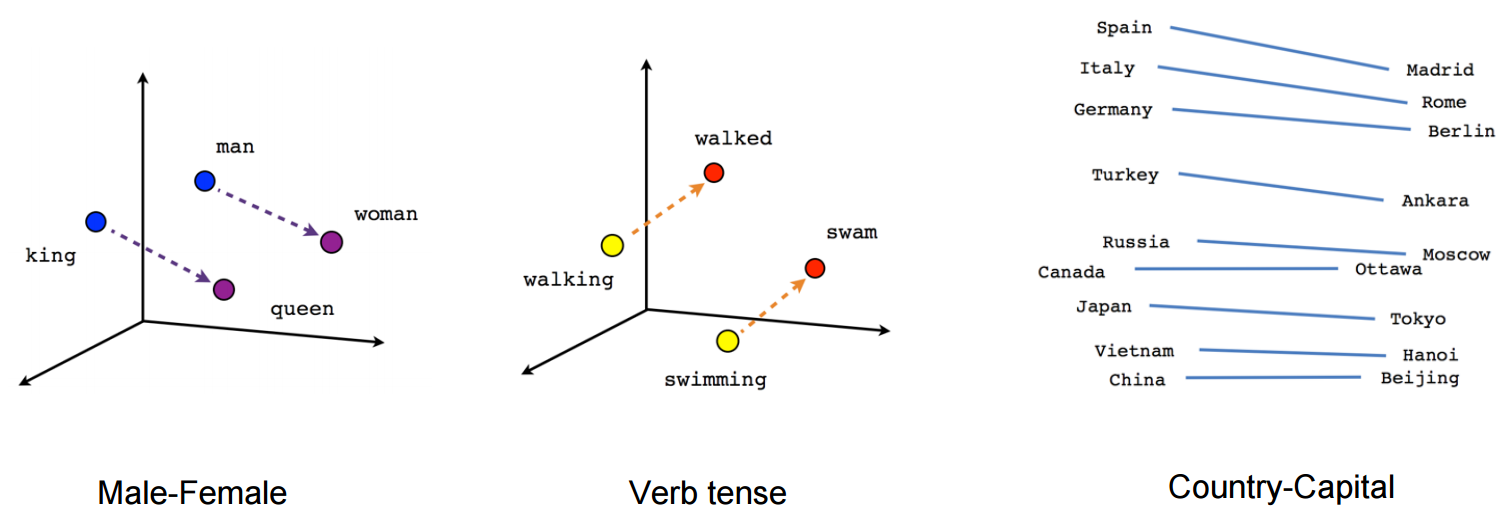
For an example, I can reach into ancient history and talk about word2vec. Remember when that was all the rage?
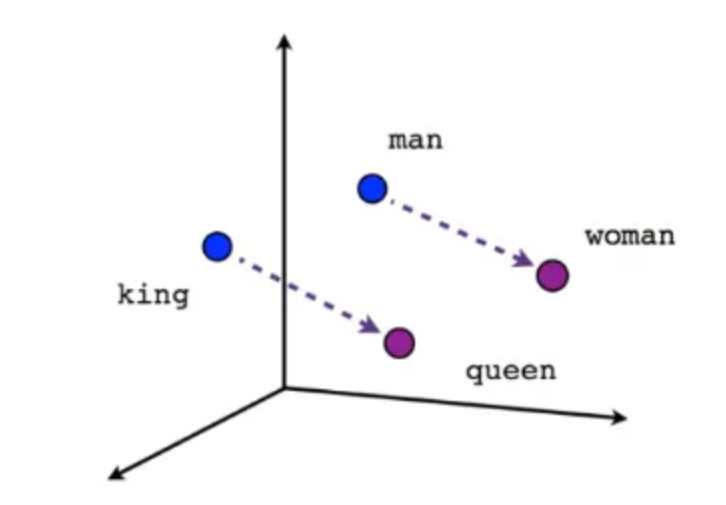
Word2vec models are trained to predict a word given its context. This is similar to a language model, though the goal is to get useful word representations (vectors), rather than to use the model for generating text. When trained properly these word vectors look like they contain something about a word’s meaning. The classic example is that the distance between the vector for king and the vector for queen is the same as the distance between the vector for man and for woman:
{kind=link}
Now, word2vec is different from an LM, as mentioned above. But I think this illustrates the idea. That just by seeing a lot of actual written text, a model can identify patterns that generally describe language, if not meaning.
But these are small, tiny models, a measly 60 million parameters (depending). What happens if they get…bigger?
Tune in next week (I hope!) for our next adventure where we put the L in LLM. The first L. It stands for Large.