 Ben
Ben 
In the last two posts, I talked about language models and some reasons people are saying that size matters. The last part of this I want to cover is something I feel is often missing from media coverage of this new era.
I understand the need to simplify things by describing technology in familiar terms. I’ve heard the “language model” objective being described as “autocomplete”, as in the autocomplete that we see in our phones, emails, etc. And I think that’s a great way of explaining it.
However, ChatGPT is not JUST a big honking autocomplete. It delivers concise (for the most part), relevant answers to natural language questions. And that difference is what made GPT go from an interesting development in NLP to an international sensation.
Learning from example - Instruction Tuning
One of the concepts I touched on in the last post was few-shot learning; where a model can learn to perform well on a task by being given a few examples of questions and answers. It appears that this is true for performance on tasks generally, as was found by in a 2022 paper by Google Research.
The Google paper called their new model Fine-tuned Language Net, or FLAN. It was trained on a variety of NLP challenge questions formatted as prompt-response pairs. You can see pretty clearly the difference training the model on these instruction datasets makes:

While the PaLM model produces sensible expressions, they’re not helpful responses. That’s basically where we were before ChatGPT; we could generate coherent passages, but that’s of pretty limited utility. The fine-tuned PaLM model (Flan-PaLM) produces much more useful responses.
This is typically called “instruction fine-tuning”, since you’re fine-tuning the model on some sets of instructions.
So since the FLAN model understands instructions, we can basically rely on it for everything now. I wonder if I can ask it for medical advice?
 source source |
That’s great, seems like ChatGPT isn’t so confident.

What’s interesting is that ChatGPT seems to be aware of its limitations, where as FLAN will basically tell you it’s an expert in everything. This is (at least in part) due a process called “alignment tuning”.
Learning not to destroy humanity - Alignment Tuning
Quick note - I’m (attempting) being funny with this title. Some notes on why alignment tuning may not quite live up to the name later.
Though FLAN was an impressive step, it’s not particularly surprising that tuning a model to be responsive to instructions means it’ll perform better on instruction benchmarks. But there’s been criticisms of these types of benchmarks that they don’t really represent “real world” situations. Just because we’ve made our LLM better at responding to particular tasks doesn’t mean we’ve made it helpful. In fact it seems like there’s ample evidence these models can do substantial harm.
This is the motivation behind the second innovation that brought us from the previous GPT era to the ChatGPT era: Alignment fine-tuning.
The term alignment comes from a general discussion about designing AI in accordance with human values. It’s not exactly a new concern

Applied to this context, it means steering a language model to produce responses that are:
1) Helpful - They should help the user solve a problem 2) Honest - They shouldn’t fabricate information 3) Harmless - They shouldn’t cause harm to people or the environment
This is operationalized in a 2022 paper from OpenAI as a fine-tuning approach incorporating human feedback. They use a method called Reinforcement Learning for Human Feedback (RLHF), which for some reason I keep reading as Real Life Having Fun.
The post I linked to (and the paper itself) does a great job of illustrating the process, but at a high level: 1) Supervised Fine-Tuning (SFT) - Take a pre-trained LLM, potentially one tuned in a useful way (e.g. instruction-tuned) 2) Reward Model (RW) - Train a reward model (usually another LLM) on prompt-response pairs, where the response has been labelled for “alignment” by a human 3) RL-trained LLM (PPO) - Generate with PPO model, score with RW, update the PPO model
My understanding is this is a grand total of three models: SFT, RW, PPO. The result is a model that has been tuned to produce useful response that are hopefully aligned with human expectations.
The result of the 2022 work was InstructGPT, which is the direct ancestor of ChatGPT. This may be a bit of an overstatement, but it’s possible without this step GPT would still be a research topic and funny twist on auto-complete.
A quick note on this - use of RLHF (or other alignment tuning) doesn’t mean the model is “aligned”. The first author of the original paper on RLHF, Paul Christiano, suggests that RLHF is a “basic tool” and that the real problems of alignment are much more complex. He notes that any approach that uses human feedback relies on the idea that humans can accurately assess consequences. This is hard to do on a day-to-day basis, much more to assess how it impacts a downstream reward training function.
But enough nay-saying, look at all this amazing stuff:

What's next?
This new era of NLP has been kind of insane. I have an old presentation where I described 2018/2019 as an explosion emoji, referring to how wild it was that we got ELMo, BERT and GPT all one after another.
And now it looks like this:
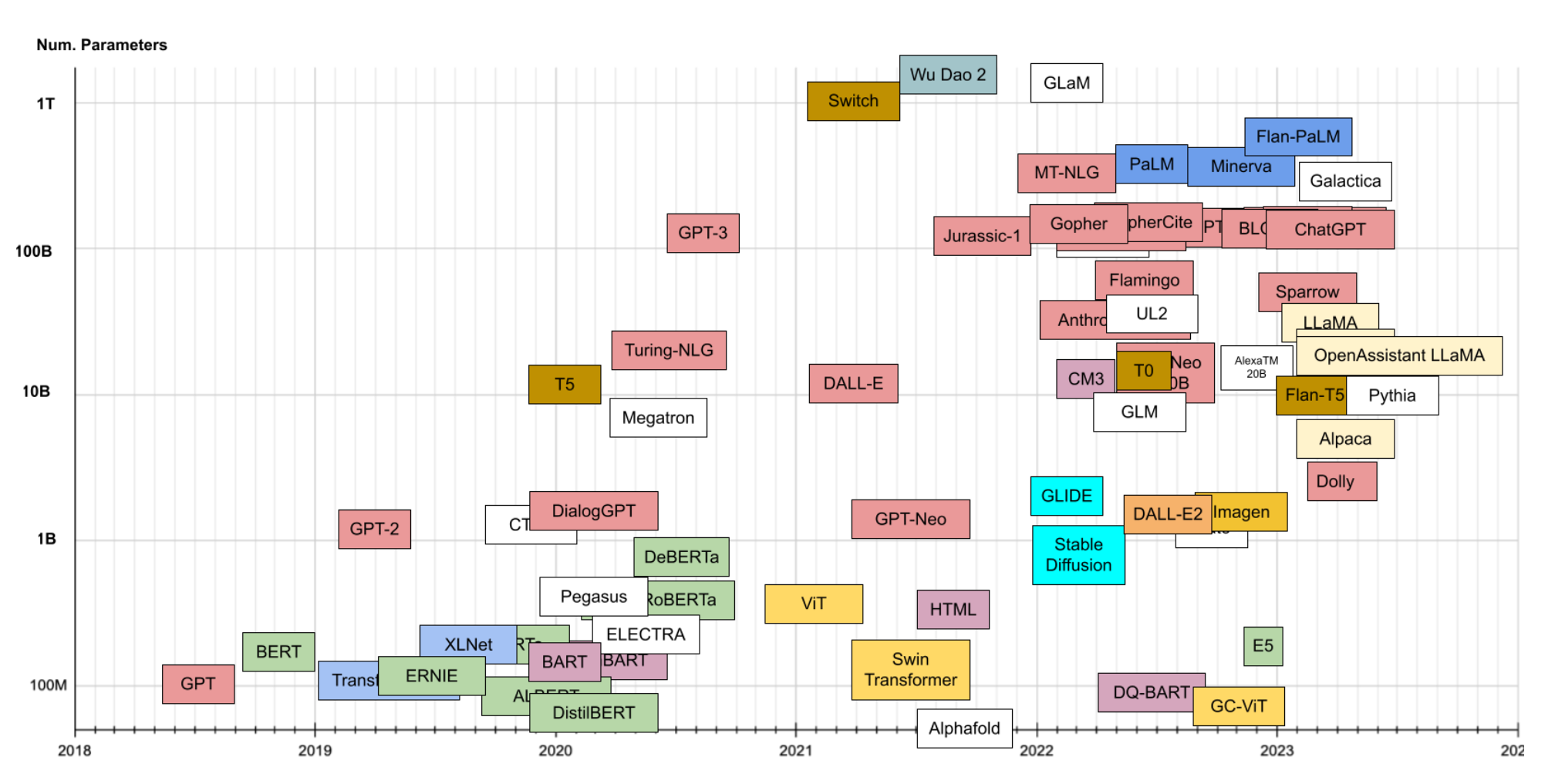
And even this isn’t up to date! We’re daily seeing fascinating advancements like running LLMs on your CPU, towns made of AI and models learning to use tools.
When people ask me the question about what’s next, I honestly feel I need to say: I have no idea!
Partially I think that’s because I have a lot of catching up to do. But partially because as cool as all these tools are, I think there’s still a need to find where they fit in workflows. I may sound like a persnickety old man here, but I still find the biggest gains come from the simplest solutions. If you’re trying to solve a problem and you haven’t tried anything - maybe try something simple before you trust OpenAI to solve if or you.
More to come on this - I’m working hard to catch up to a field that is daily advancing. Welcome all comments and suggestions, as always.
Stay tuned!