 Ben
Ben 
This month superstar LLM startup Cohere released their Command-R+ model. I experimented with this model to create a functional (and free!) agent workflow to look up local events.
What is Command-R+? Interestingly enough, that’s the name of the next section.
What is Command-R+?
Cohere is an AI startup that specializes in large language models. It was founded by researchers from Google, including one of the authors on the original transformers paper (Aiden Gomez). They work in partnership with many of the big tech dogs including Oracle, Google and McKinsey. One great thing about them is their orientation towards open science. They established Cohere for AI, a non-profit research lab led by another former Googler Sara Hooker.
In March, Cohere released Command-R, which was specially designed to make use of “tools” (see this post for how that works) and for Retrieval Augmented Generation (RAG) workflows (more here). Additionally, it was trained to be performant across multiple languages, which is an important measure of completeness in language representation.
Hot on the heels of Command-R was this month’s release of Command-R+, which improves on the performance of the previous release.
Cohere’s own comparison versus Mistral and GPT-4:
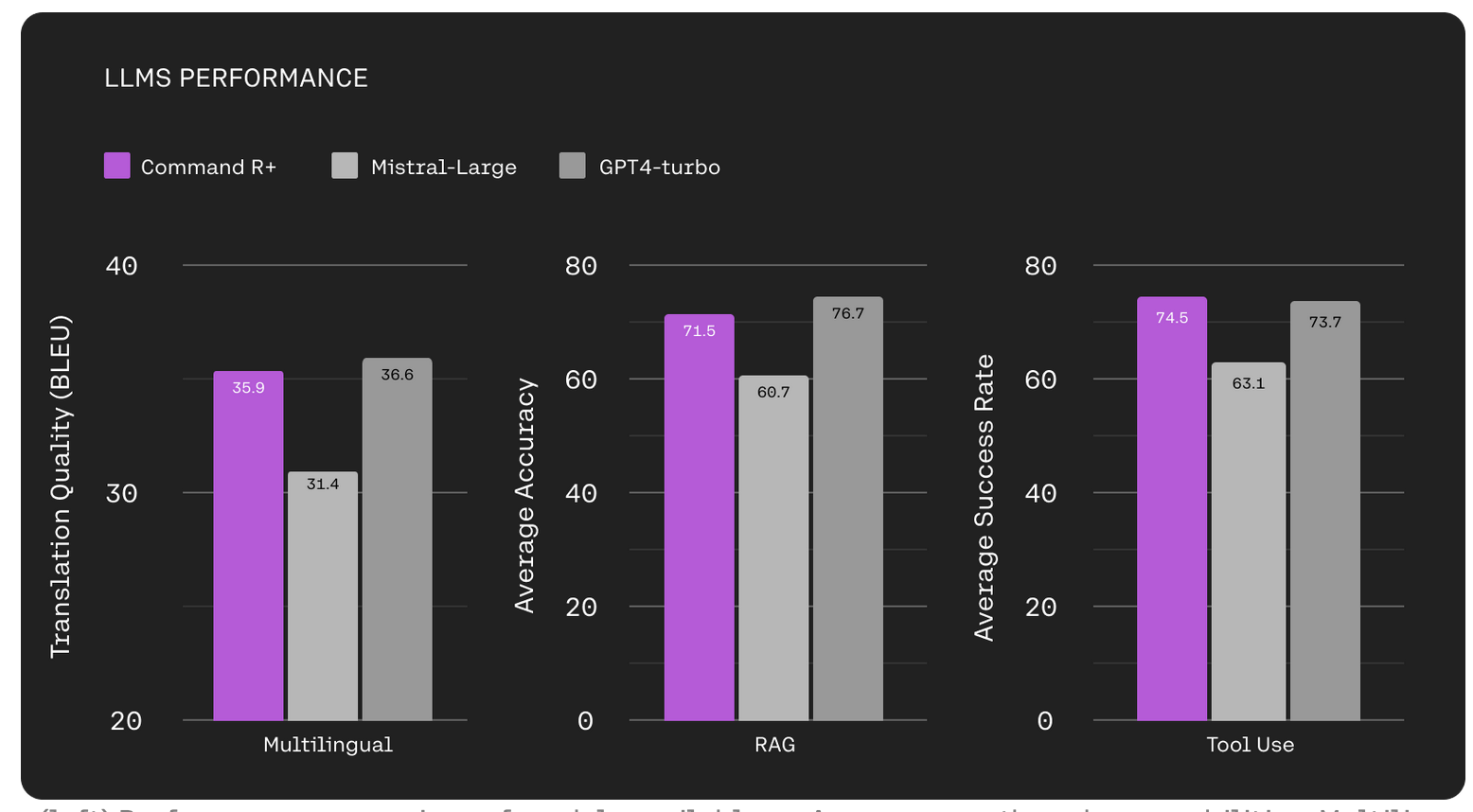
But don’t take their word for it - it’s now the first open weight model to beat GPT-4 on LMSys’ chatbot leaderboard!
The best part? You can download the model weights right now!
Cohere also offers a free tier for usage of its APIs. That enabled me to develop a pretty neat prototype agent application that you can go ahead and mess around with for free!
How does it work? I…don’t really know. Cohere released a bunch of material about the models, but the training process and complete training data did not appear to be part of that. That’s why I refer to this model as “open weight” versus “open source” (more info).
We do get some information about how the Supervised Fine Tuning process worked. The prompt has a specific structure:

The details are at the link above, but you can see that the structure is much more specific to a tool-use workflow. Because the model is trained on this structure, it is more able to output structured actions specific to the tool set provided.
Command-ARR+
If you’re a regular reader, this example might look familiar from my post on developing LLM agents. I basically adapted the example for Cohere which, thankfully, has a nice little wrapper in LangChain. I needed to do some refactoring of the tools and the prompt itself as well.
Check out the full notebook implementation.
A few things I want to point out here. Whereas with OpenAI we needed to use a pretty detailed ReAct prompt structure, Command-R+ is specifically designed to interact with tools (as described above).
So the “preamble” is simple:
You are an expert who answers the user’s question with the most relevant datasource. You are equipped with tools for getting date information and looking for upcoming events.
I found with a generic “you are an expert”-type preamble, the agent often stumbled over figuring out what to do.
Specifying the tools is also different from use with LangChain+OpenAI. The output of the Command-R+ model is expected to be structured json that looks like:
{'tool_name': <tool_name>
'parameters':
{<param_name>: <param_value>}
}
For this to work consistently, I needed to specify some information about the tool parameters using LangChain’s BaseModel class:
class empty_string(BaseModel):
text: str = Field(description="Empty string input", required=False, default='')
@validator("text")
def is_empty(cls, field):
if field is None:
return ''
return field
class date_input(BaseModel):
text: str = Field(description="Date string in the format YYYY-MM-DD or weekend number (e.g. 1)")
today.args_schema = empty_string
weekend.args_schema = empty_string
get_events.args_schema = date_input
You’ll see here I needed to customize the parameter validation. This is because the model often output no parameters or empty parameter values for the today or get_weekend functions. LangChain would complain about that and it seemed like the best approach was to customize validation of the output (rather than rewrite the parser).
In this notebook, I also experimented with including a “styling” prompt, asking the final answer to be delivered in the style of a pirate. There were two ways I could think to do that:
1) Include the styling prompt in the preamble 2) Pass the output of the agent workflow to a styling call
I found that the workflow sometimes broke if I included the styling prompt in the preamble. Sometimes it would just output a long “ARRR” as its final answer. Which, honestly, could be accurate in pirate terms. I don’t know many pirates.
Example with no style:
This weekend, you can visit Sarma in Somerville for Turkish and Mediterranean small plates, Esthetic Bean in South Boston for coffee and waffle sandwiches, or Yvonne’s, a modern supper club in downtown Boston.
Example with preamble-based styling:
Argh, ye scurvy dog! Ye be wantin’ to know what be happenin’ on the weekend, aye? Well, listen up, ye landlubber!
This here weekend, we be havin’ some fine live music at The Bebop in Back Bay. Aarrr! Ye can swing by and enjoy the sweet sounds of the sea while downin’ some grog.
Example with post-generation styling:
Arrrr, ye scurvy dog! Ye be wantin’ to know what be happenin’ on the high seas this fine weekend, arr you? Well, listen up, ye bilge rat!
Saturday be the day for a swashbucklin’ tour o’ Fenway Ballpark. Ye can imagine yourself as a mighty captain as ye stroll the grounds. Come Sunday, there be two choices for ye: a Resin Jewelry Workshop, where ye can craft some treasure to adorn yerself, or ye can listen to the sweet sounds of the Brentano String Quartet.
One nice feature of the output of these models is the “Grounded answer” - where it will provide an output with citations to indicate which document it used to generate the answer. I didn’t play much with that for this workflow, but I can imagine it being useful for general RAG workflows.
Final thoughts
This was a great exercise and it’s pretty impressive what a model tuned for tool use can do. I still felt like I needed to spend time customizing the inputs to achieve the desired workflow. At a certain point, it makes more sense to just build the workflow directly rather than coaxing the right answers out of the LLM. One theory I have is that maybe stitching together multiple agents might accomplish this “fully-functional” assistant. That seems borne out by the success of the “post-generation styling”.
Cohere’s models are great, though, and having free access to the API for prototyping is awesome. Their models on HuggingFace are still pretty big, so not having to manage resourcing that is a big plus.
I’m still cranking away on my upcoming ODSC tutorial. Bunch of material on that soon to come!
 Teaching text representation techniques
Teaching text representation techniques