 Ben
Ben 
This is part 3 of my series on LLM application development, see the previous two parts:
Ollama, LlamaBot and Oobabooga
If you’ve been following along, I set up a pretty simple framework for what I’m calling a conversational LLM application:
- Frontend - The user interface, as with other applications
- Input processor - Translate the user interaction into model input
- Model - In this case, the LLM itself or whatever service is hosting the LLM (e.g. OpenAI)
- Memory - Context storage
- Output processor - From model to user
In a lot of the examples we saw in the previous post, the input and output processors essentially involved the same set of components. The user input is translated to “LLM language” and then the output is translated back. To make this conversational, we added a component that includes the conversation history along with the user prompt. You can think of this history augmentation as an example of “in context learning”. I describe that more fully in my series on LLMs.
Now what if you wanted to include something from outside of the conversation history? “Like what?” I hear you asking eagerly.
Who’s the boss?
The platform formerly known as Twitter has undergone a lot of changes recently. I’m curious who the current CEO is. Why don’t was ask Anthropic’s Claude model (using Poe):
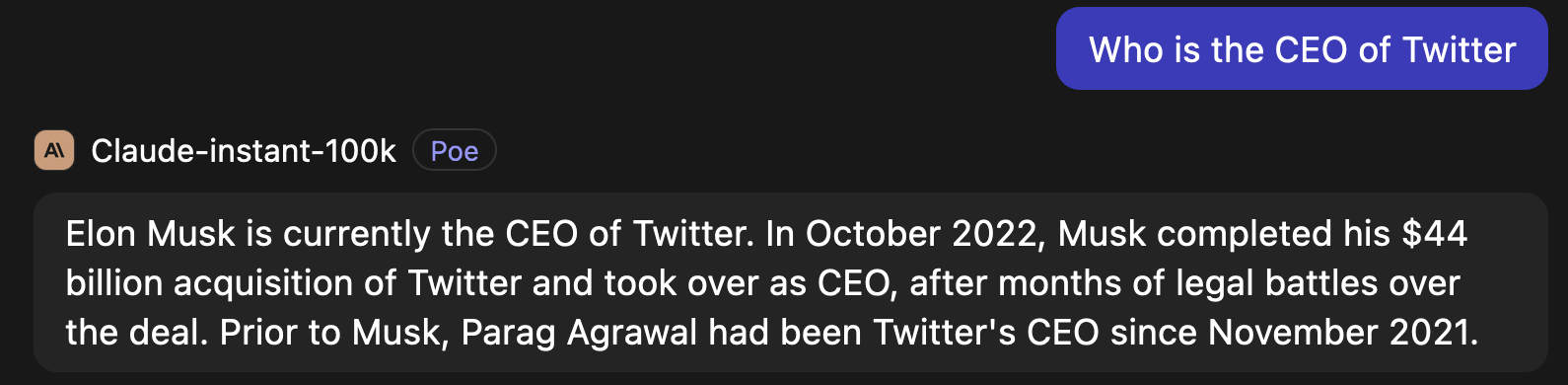
But is he? I seem to remember some problematic comments he made.
Why don’t we just check another bot just to be sure. Poe’s “web search” bot conducts a web search in the background based on our input. It then passes the our input and this web search information to the LLM.
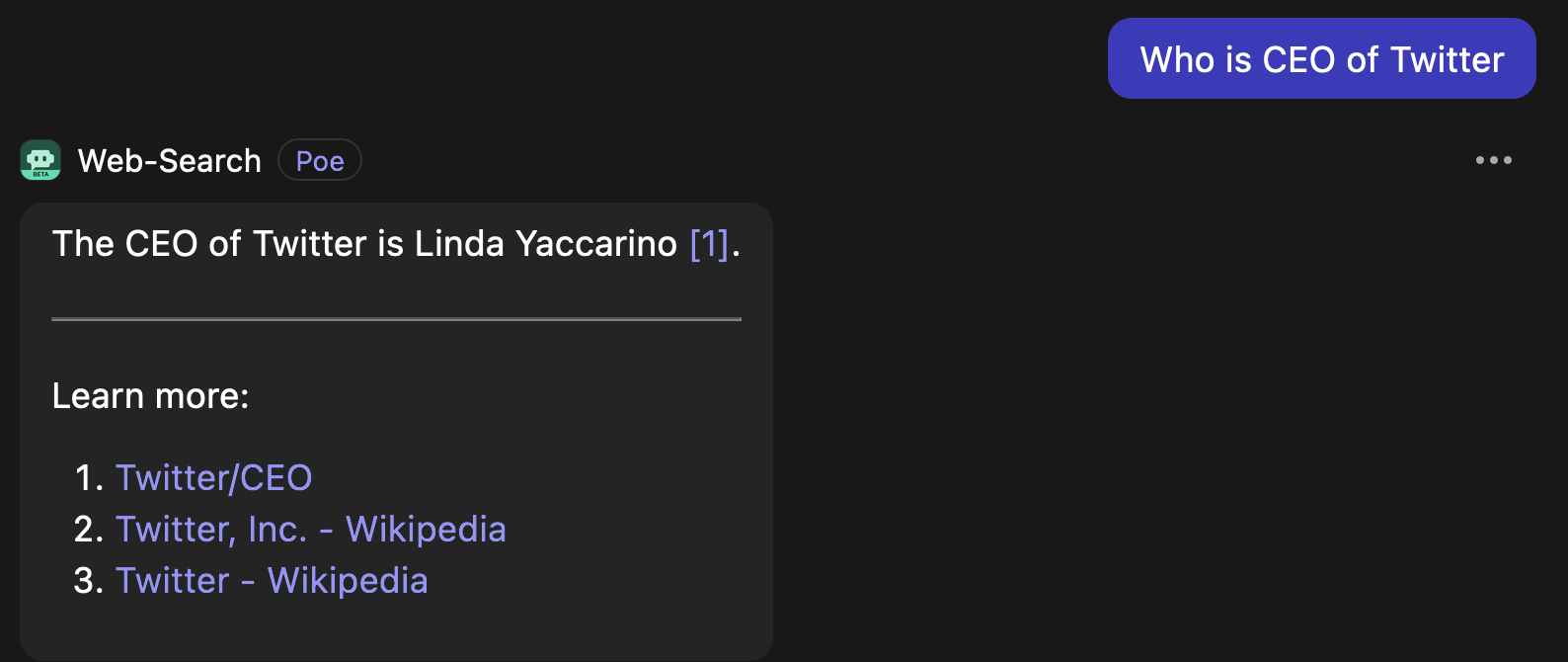
For bonus points, it even cites its sources.
This example points to two major issues with LLMs:
- Out-of-date training data - Claude’s training data only extends to the end of 2022. Perry died this year, so there’s no way it would have information about that event.
- Hallucinations/Errors - LLMs routinely produce false information, often called “Hallucinations”, though you could just as easily call them errors.
One way to address these issues by doing what Poe’s web search bot does; augmenting the input with relevant information from a web search. Or, in fancy acronym language: “Retrieval Augmented Generation” (RAG). The result, in this example, was a factual, up-to-date response.
“How does it work?” asks the eager reader.
RAG stack (pile?)
A 2021 article by Meta researchers took a step forward in the use of RAG with LLMs. Their RAG+LLM workflow is a top performer on Question Answering (QA) tasks. The “retriever” part is similar to other QA systems; it “encodes” the user’s query and then compares that encoding to a the encoding for a document or set of documents. The idea is that if a document is “similar” to the query, it’s probably relevant to the query.
(Note - I talk about encodings/representations and their mathematical properties in my series on LLMs)
The retriever, then, performs the following actions:
1) Encode the user query 2) Compare the encoded query to a set of documents 3) Return the relevant documents
“Document” here can refer to individual documents, paragraphs, sentences, etc. To compare these documents to the query, both need to be encoded in some way. For the documents, it makes sense to encode them ahead of time so that you’re not re-encoding your library on request. Typically an encoding is two-dimensional array of numbers - a vector. So we can also refer to our stored encodings as a “vector store” or “vector database”.
So our RAG stack would look something like:
- Retriever
- Vector store
- Encoder
But that’s not all! Right now all we get out of this system is a set of documents. Just the “R” in RAG. So how do we augment the generation?
The Meta paper is a bit complicated, it builds a whole learning system around this component. A more simple approach is to just pass the document as context to the model (i.e. include it in the prompt). Essentially, we’re augmenting the models “memory”. Now, not only can the input contain a conversation history, it can also include relevant documents retrieved by our system.
And so we get our retrieval-augmented conversational LLM application:
- Frontend
- Input processor
- RAG stack - Retriever, vector store, encoder
- Model
- Memory
- Output processor
I’m putting the RAG stack within the input processor - since that’s the component that performs these functions. In this case, the input processor looks different from the output processor. As these applications become full “agents”, the two sides might deviate further.
Enough talk! Let’s see some code.
RAG with LangChain
One of the projects I’ve been working on is with a group called Link Health, which aims to facilitate individuals’ access to federal programs like the Affordable Connectivity Program. They want to be able to ask applicants a series of questions and, based on the answers, automatically determine eligibility and start the application process. In order to do that, they need to extract the eligibility requirements from program materials and then format them into a set of questions.
This “formatting” challenge is right up an LLM’s alley; essentially a question of “style transfer”. But being able to extract the relevant information from a long document seems like a good fit for our RAG workflow.
We’re going to use one example document detailing the eligibility requirements for a set of Medicare Savings Programs. This is saved as a PDF for ease of use, available here on the github repo for this series.
Here is a notebook with the steps we’ll be using. I could only get this to work on the free tier GPU. Note that there’s limits in how much compute you can use here for free.
Our RAG workflow here uses Llama 2 as our encoder, made available through the magic of Ollama. The encoding comes from the model’s internal representation of the sentence (see note below!). You’ll see in the notebook this representation is of dimension 4,096. As with word embeddings these dimensions aren’t themselves interpretable, but they are useful for comparison with other representations.
Now, remember, this encoder is used for both the documents and the query. Our “documents” in this case are short chunks of the full PDF. These chunks need to be stored and compared against the input query. This part is managed by LangChain and FAISS.
FAISS is an efficient implementation of vector search based on similarity. Just think of it as simple and quick way to do the kind of comparisons we need for matching a query to documents.
Why do I use it? Because it’s pretty fast and low-effort to implement. I don’t know enough to tell you the tradeoffs between it and, for example, ChromaDB (which is what some other tutorials use), but it worked out of the box, so I’m using it.
Let’s loop back to thinking about what the “stack” for this application looks like. In this use-case, there’s no real reason to make it conversational. So we won’t be including a “memory”, each query to the system will be treated independently:
- Frontend - Jupyter notebook
- Input processor - LangChain, Llama 2 (Ollama), FAISS
- RAG stack
- Retriever - LangChain
- Vector database - FAISS, LangChain
- Encoder - Llama 2, LangChain
- RAG stack
- Model - Llama 2
- Output processor - Base python code
We might just condense the input processor into a single line, but I expand it here so we see what the system looks like underneath.
Here we run a few experiments just to see the difference in the LLM’s outputs.
Experiment 1 - Full text, no RAG
In this experiment, we just ask the LLM to do the task, providing the entire document as context. Of course, this won’t work if your document is very long, but in this case the document fits within the context window. The result is pretty interesting - it does seem to do a good summary containing accurate information. Interestingly, it’s more in a kind of Q&A style, not the list of questions style we want.
Run this a few times and see what you get. Because we don’t put restrictions on generation, we’ll get different results each time, so you may see some different results here.
1. What's a premium, deductible, coinsurance, or copayment?
Premiums are the fees you pay for health insurance, deductibles are the amounts you must pay out of pocket before your insurance coverage kicks in, coinsurance is the percentage of costs that you and your insurance provider share, and copayments are fixed amounts you pay for certain medical services or drugs.
1. How to qualify for the 4 Medicare Savings Programs?
To qualify for the Medicare Savings Programs, you must have income and resources below certain limits. These limits vary by state and year, but generally, individuals with income below $1,235 per month and resources below $9,090 may qualify. Some states also consider other types or amounts of income or resources when determining eligibility.
--truncated for brevity--
Experiment 2 - Two-stage query, no RAG
In thinking about the above, I wondered if I passed a more condensed input to the “question generation” task it would do a better job of doing that task. This is related to the logic of RAG works, but here I wanted something that was kind of a midpoint between the two. First, I asked the LLM to extract the eligibility requirements from the full text, then I passed that output along with a request for formatting them into questions. The result is more in line with our requirements, but often it will provide incorrect or irrelevant questions. Likely this is STILL too much information being provided into the context.
Here are the questions that an applicant might be asked to determine their eligibility for the Medicare Savings Programs:
1. Do you have a valid Medicare card?
2. Are you enrolled in Part A and/or Part B of Original Medicare?
3. What is your income level? (To determine if you meet the income limits for the program)
4. What are your resources, such as savings accounts or assets? (To determine if you meet the resource limits for the program)
--truncated for brevity--
Experiment 3 - Bringing in RAG
Enough messing around, let’s get RAG-y. In this setup we’ll use a similar query to experiment 1, but we’re not passing the full text of the document. In this case, the query is encoded and compared against the document “chunks”. The relevant chunks are returned and then passed to the LLM as context. LangChain has some formatting of this kind of LLM input under the hood.
We see that the result is similarly compact as with experiment 2 - just a list of questions to the applicant. We also see much more relevant, accurate information. In this instance, it actually gives us the specific income limits.
Based on the provided context, here are the eligibility criteria for the Medicare Savings Programs as rephrased questions to an applicant:
1. Are you a resident of a state that participates in the Medicare Savings Programs?
2. Do you have Medicare Part A and meet certain income and resource limits? (For example, your monthly income limit is $4,945 as an individual or $6,659 as a married couple, and your resource limit is $4,000 or $6,000 respectively.)
--truncated for brevity--
One thing you’ll notice here is that the income limits are for one specific program. Oh no! Turns out the document actually has details for four separate programs. The retriever only returns a limited set of chunks. Ideally that’d be chunks corresponding to each of the programs’ requirements but life is never so simple.
With some reconfiguring of the parameters and some attention to the document inputs, you can potentially get to your goal of extracting the full set of eligibility requirements for each program. But it’s not something you get for free. RAG is a powerful tool, but it doesn’t free you from the need to pay attention to your data!
Summing up
In this post we went over the why and the how of Retrieval Augmented Generation (RAG). We saw how including a RAG component in an LLM application stack can achieve more useful, up-to-date and accurate results. This doesn’t mean the application can do everything, we still need to be smart about our design.
In my next post I’ll return to the conversational application. So far we’ve been using the standard, public version of the 7 Billion parameter Llama 2 model. It definitely has a tone, way of “speaking”. What if we want to adjust that tone? For example, to make it talk like a medical professional? Well, we’d need to “tune” that tone.
Stay (fine) tuned!
Some useful articles
There’s a LOT of excellent materials I relied on for this post. Here are a few of them:
Article on RAG by Meta Researchers
LangChain overview on how to use RAG with local models
Small addendum
I maybe spent too long trying to understand from where, exactly, the embedding/encoding from Ollama comes. I couldn’t actually answer that question, though it seems I’m not alone in being curious.
Since this embedding likely comes from Llama itself, it may actually NOT be appropriate for our RAG system! Llama is not trained to compute similarity between documents, so using its representations to do so may be problematic. There are, however, models trained to produce usable embeddings. I may experiment with these down the line, stay tuned!
 LLM technology for dermatology
LLM technology for dermatology