 Ben
Ben 
It’s a wrap! ODSC East 2024 has come to and end and what a ride it was. I’ll have another post next week on the materials from my LLM application workshop, but for now I wanted to get down a recap of some of the talks I went to while it’s still hot and fresh.
DISCLAIMER All images here are the property of the speaker listed!
Learning from Mistakes: Empowering Humans to Use AI in the Right Way
Hilke Schellmann, NYU
Hilke’s keynote was a really interesting exploration of some of the problematic applications of AI. She focused particularly on the use of AI in hiring. One example she detailed was a company called HireVue, which touted its use of facial expression analysis to identify the suitability of a candidate. She referenced a WSJ report on the subject
She made the point that there’s no scientific grounding for the expression analysis used in this technology. Though HireVue no longer uses these factors, there are other companies that do. She calls out a really interesting analysis where just adding a bookshelf to the background of an image drastically changes the values on a “personality analysis” technology.

Imputing Financial Data Using Generative AI
Arun Verma, Bloomberg
Arun gave a broad overview of the role of ML at Bloomberg, covering needs such as:
- Asset pricing
- Factor investing
- Insights and Signals from alternative data (e.g. ESG data)
- Anomaly detection
He pointed out that there’s some contention between what is typically called “quantitative finance” and AI. Specifically, AI makes few assumptions about the data and instead targets predictive performance. This is in contrast to traditional quantitative finance which focuses on building models based on deep analysis of the statistical properties of the data.
Arun explains that both have a role in the organization and goes on to detail some useful applications of generative AI at Bloomberg. The one I understood best was the use of GAI to generate “realistic” market data that could be used for training and analysis. There are common factors that can be extracted from performance data across stocks. To project these values forward, Arun described using GAI as a method for generating values for these factors.
Building AI Systems with Metaflow
Ville Tuulos, Outerbounds
The main thing I took away was the idea of a LLM-supported shopping workflow. Essentially, a customer would detail exactly what they’re looking for and a GAI system would generate an image that is a composition of different products in the catalog. Then the user would engage with these different elements and to get additional information about the products. This information would itself be generated by GAI systems.
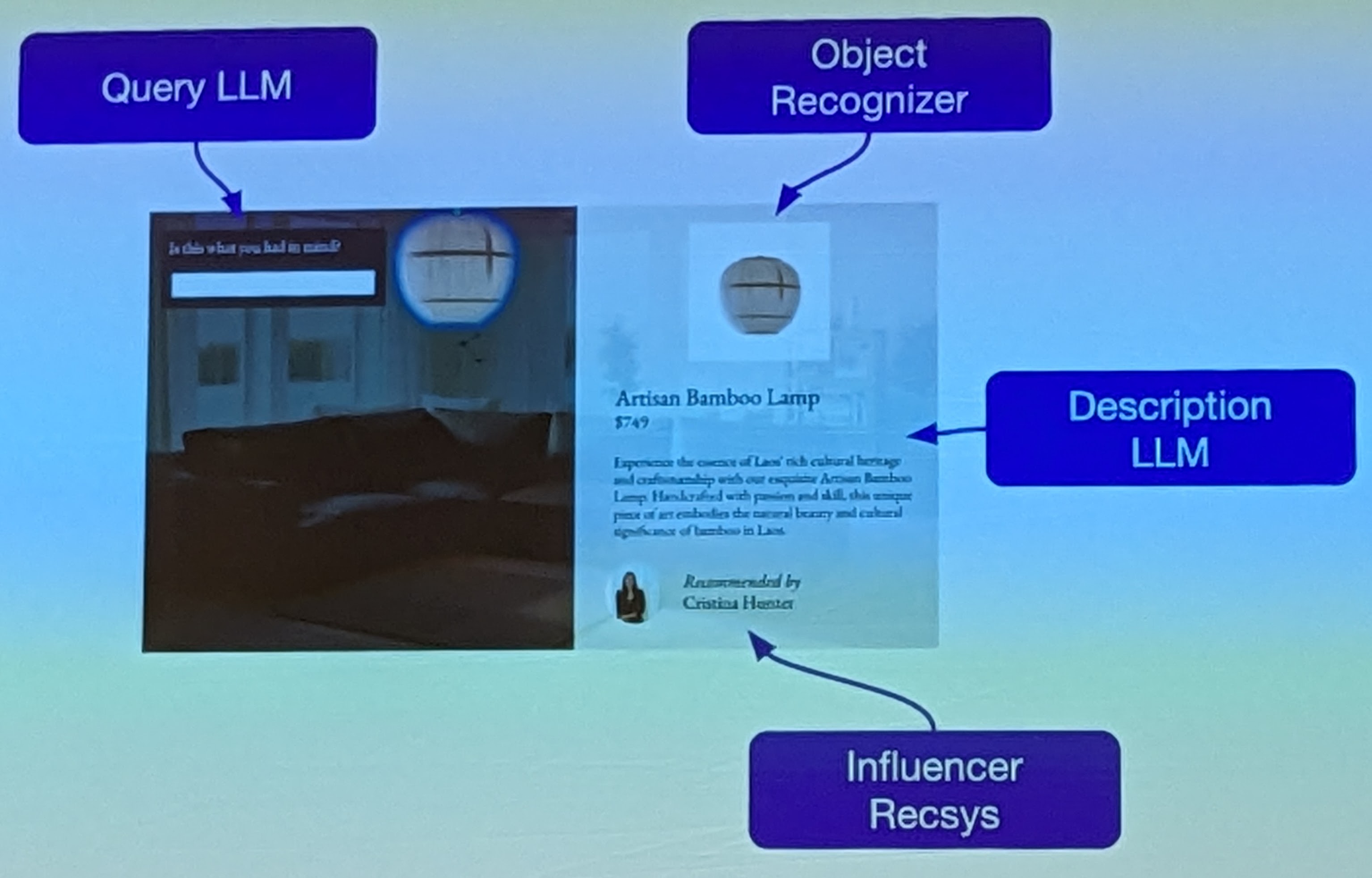
This is a cool idea from which I think we are very, very far. Ville’s point here, I think, was something like that; each system requires its own support architecture and to build something like this would require building out an elaborate system structure.
Personally, though, I just want to know if my size is in stock.
Flyte - Open source AI platform
Thomas Fan, Union.ai
Thomas introduced an awesome new open source technology called Flyte. Flyte basically breaks down ML workflows into sets of tasks which can be composed into a workflow. Each task can have its own image and resources. Each component is defined in a simple, pythonic way. Additionally, there is native integration for scaling technologies like Spark, Ray and Dask.
The syntax reminds me a lot of how Modal works, but is agnostic to the cloud provider. I definitely need to dig into this further.
Tracing in LLM applications
Amber Roberts, Arize AI
Amber introduced Phoenix, an open source component of the larger Arize observability platform. Phoenix is focused on giving better visibility into the workflow for LLM agent systems. In my agent workflow with Command-R+, I have an example of a simple workflow:
- Get the current weekend date
- Use that information to extract upcoming events
- Return the result to the user
Phoenix is designed to track those workflow “traces” and surface the results in an easy-to-use dashboard. Phoenix uses the concept of “spans”, which I didn’t fully understand, but appear to refer to individual components of the workflow. It’s specifically well-designed to run and track evaluations. The example Amber described was using an LLM to grade the response from the agent workflow (i.e. whether the response is factual/relevant).
Preserve Exact Attribution through Inference in AI
Chris Hazard, Howso
I had an interesting conversation with this speaker about his technology though I will fully admit I didn’t fully understand it. In this talk he outlined the “ideal state” where in something like Natural Language Generation we’d be able to understand the source responsible for each generated token. For example, if wikipedia contributed to the prediction, that should be able to be extracted. This is a focus on “data” attribution versus model attribution. Rather than analyzing which features contributed to a prediction, the goal would be to analyzing which data points contributed to a prediction.
There was more to this, but I don’t want to misrepresent it, so I’ll just point folks to Howso’s github, where they have open-sourced the engine behind their technology.
Algorithmic Auditing
Cathy O’Neil, ORCAA
Unfortunately, I missed most of this talk, but I did want to call it out because there were some really interesting points. For one, she proposed the idea of an “ethical matrix” for assessing risks in a particular system. The rows here are the stakeholders and the columns are the risks. Color-coding gives a simple at-a-glance look where to focus attention on analysis and mitigation.

She also made the excellent point that algorithms are inherently discriminating. If you’re building a classifier, the whole objective is discrimination. The goal for auditing these algorithms is to ensure (as much as possible) that that discrimination is justified. She gave an example of a job fitness score that appeared to assign higher scores to men than women. However, when years of experience was factored in, the difference disappeared. This doesn’t necessarily mean all is well, since years of experience may have inherent bias in fields that have traditionally excluded women. But at least it provides an explanation of the differences.
LLMs as building Blocks
Jay Allamar, Cohere
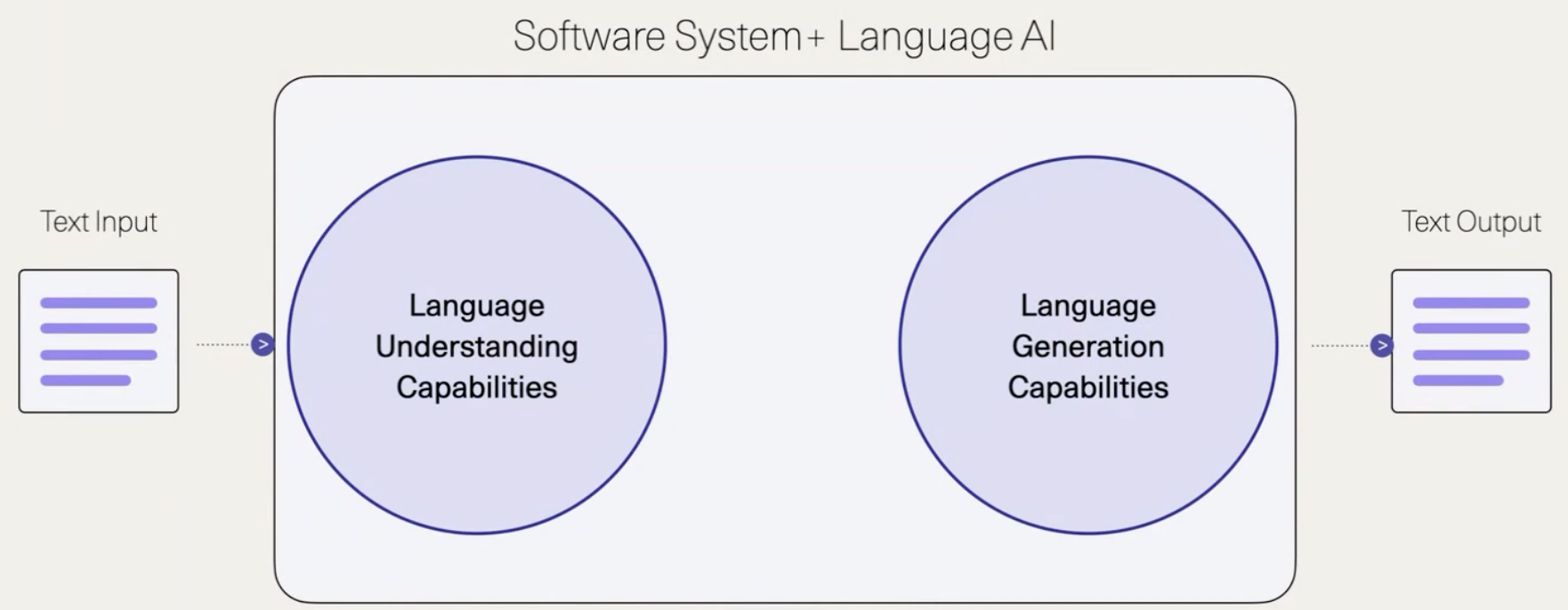
The man himself! I was very excited to attend this talk - Jay does an excellent job explaining complex topics. Here he broke down a complex LLM-driven system into individual components and explained how each component may benefit from having its own specialized model.
We start here - breaking the LLM system into an “understanding” and a “generation” component:
And we get to here where we’ve modified the generation capabilities to fit our particular purpose, be that search, question answering or just plain old classification.
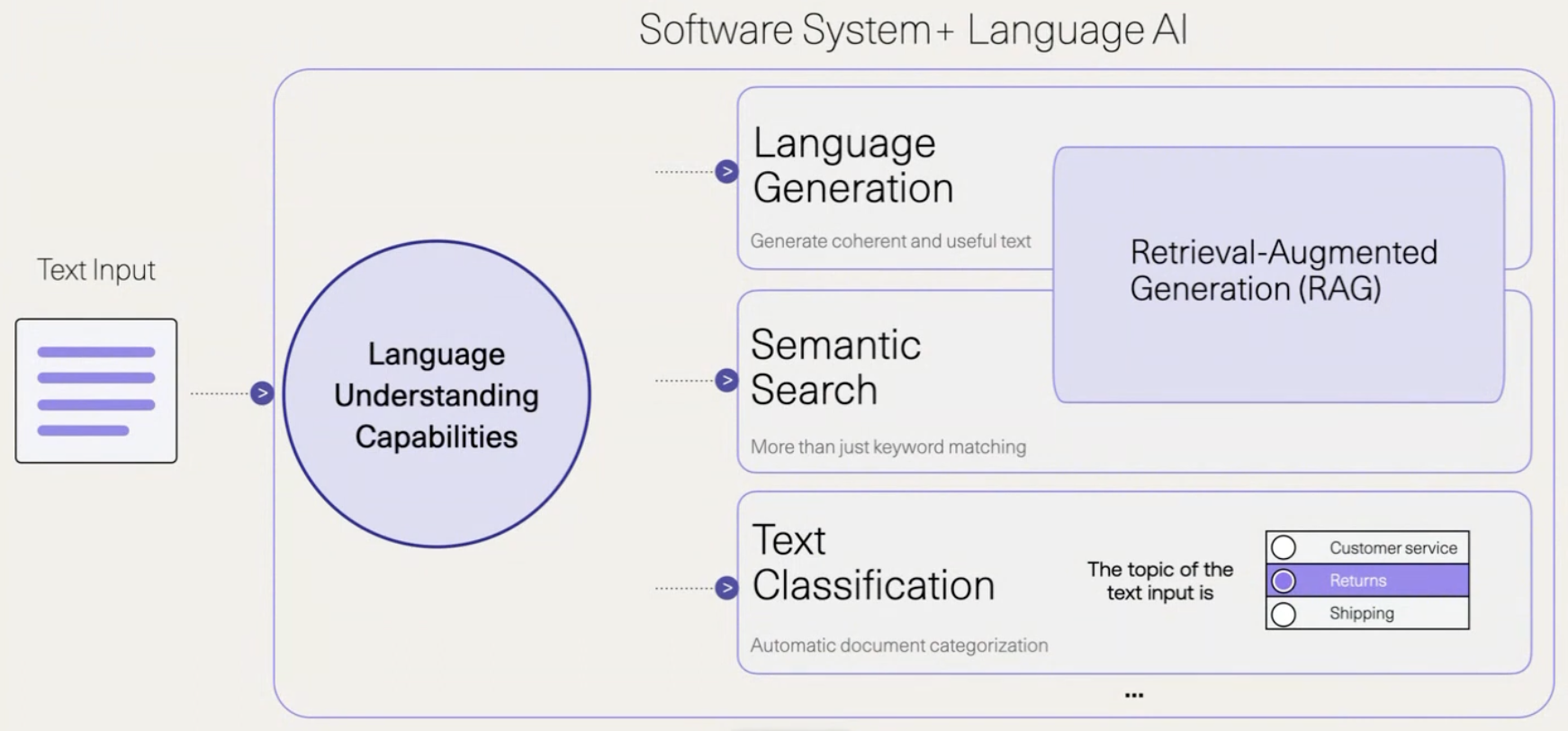
(Note: I discuss RAG in a previous post if you’re interested)
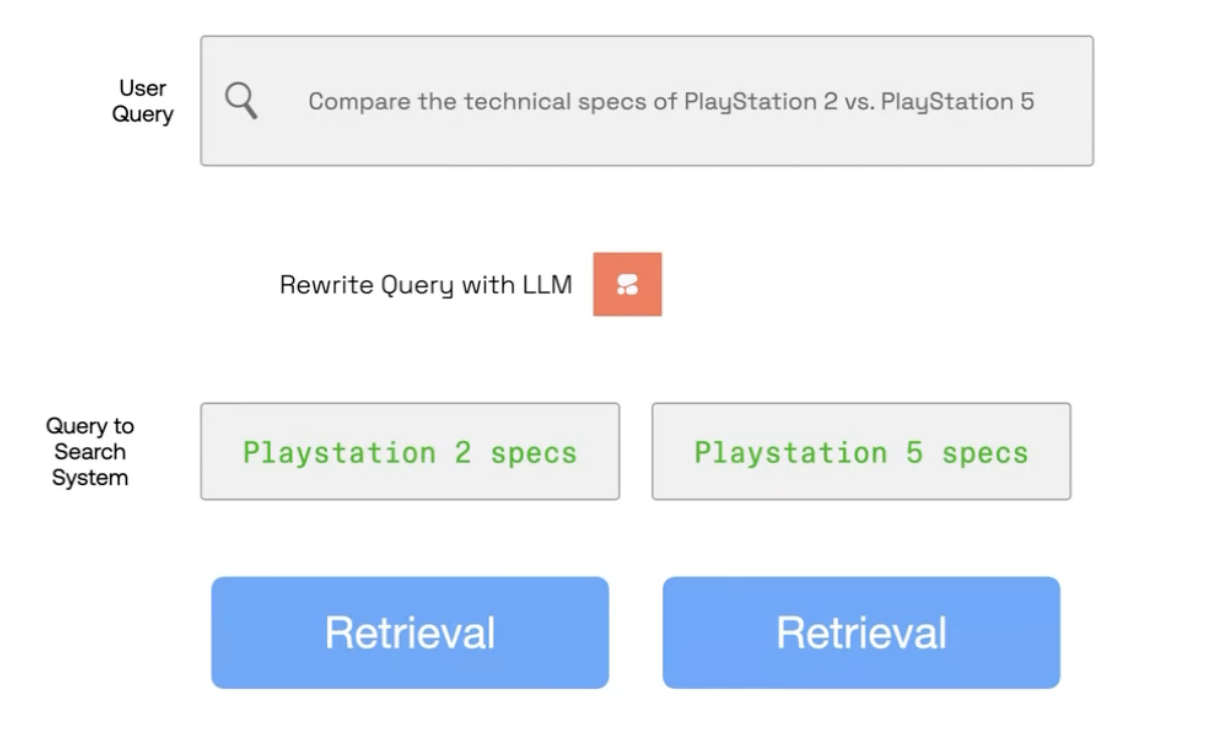
Jay also covered a few cases where a user query needs additional processing before it can be used for search. In one case, the query is a bit all over the place and needs to have a question extracted from it.

In another, there are two questions, each which need their own answer in order for a comparison to take place.
Model Evaluation in LLM-enhanced Products
Sebastian Gehrmann, Bloomberg
This was an excellent talk about what’s missing from LLM evaluation. Sebastian explained that although Natural Language Generation has made incredible advancements in the last few years, evaluation approaches have mostly stayed the same. That is, models are tested against general purpose benchmarks. This is useful for measuring the “general” capability of the model, but models aren’t being used for “general” applications.
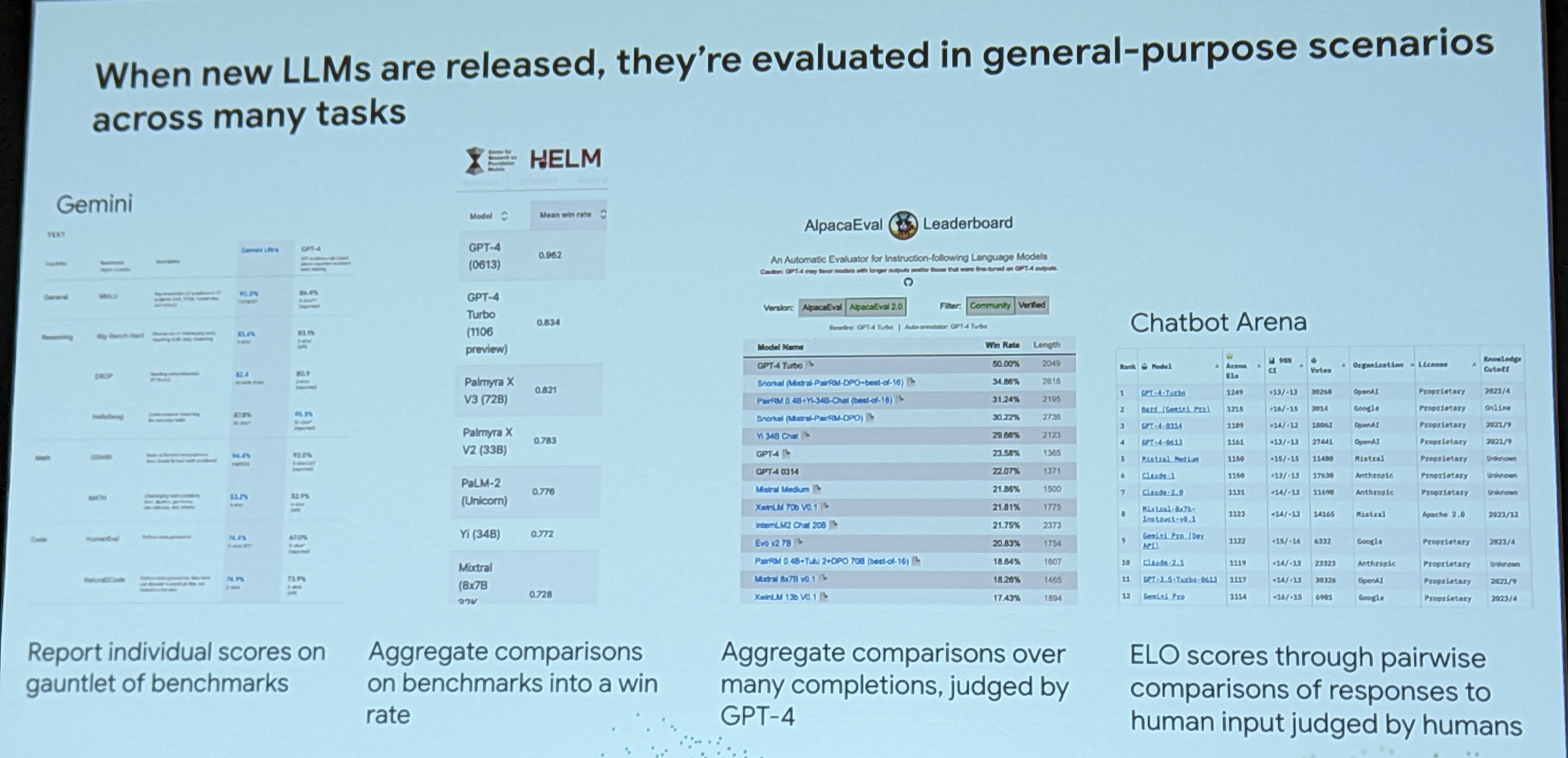
He points out that ROGUE, a typical measure for summarization, doesn’t correlate well with human judgements about summarization quality. He calls for the building of use-case specific evaluation structures. He proposes creating an evaluation suite, an example of which he demonstrates:

This process of developing an application-focused evaluation stack should be part of the product development step.
 Building a Command ARR+ agent
Building a Command ARR+ agent