 Ben
Ben 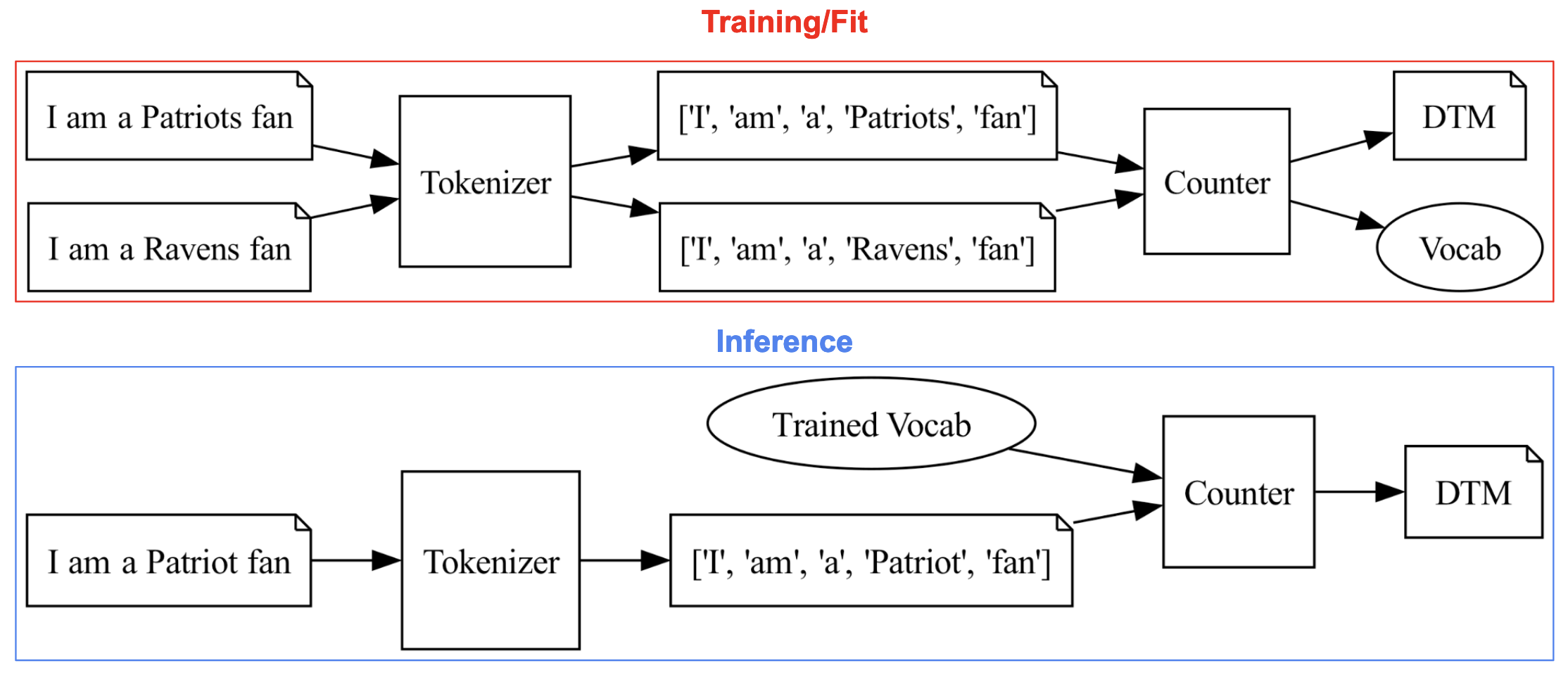
I swear, I’m still here! The past few weeks have been a bit of madness with job transition, travel, etc.
One of the things I was working on was putting together an update to my Bagging to BERT tutorial for a presentation to the Census’ Center for Optimization and Data Science. Because every talk needs to have a catchy name, I called it:
I’m pretty happy with how it came out. I ended up spending a lot more time talking about tokenization strategies and how, in my opinion, they constitute an example of “transfer learning”.
This is how I visualized it:
 |
|---|
| Tokenization as transfer learning |
At “training” time, you create a vocabulary which constitutes all tokens you expect your system will encounter. There’s no practical way to capture every possible token, so your assumption is that the task to which you’ve fit your vocabulary is a good representation of the task you’ll be doing at inference time.
That sounds a lot like transfer learning to me.
I like this way of thinking about it. Tokenization, from what I’ve seen, is sort of hand-waved away as a little pre-processing step. But, in the words of Bush, it’s the little things that kill. One of the reasons the big bad GPTs struggle at times with math has been theorized to be because of tokenization. That is, because GPT is not specifically trained to tokenize components of mathematical equations, it struggles to answer questions about them.
From my presentation:
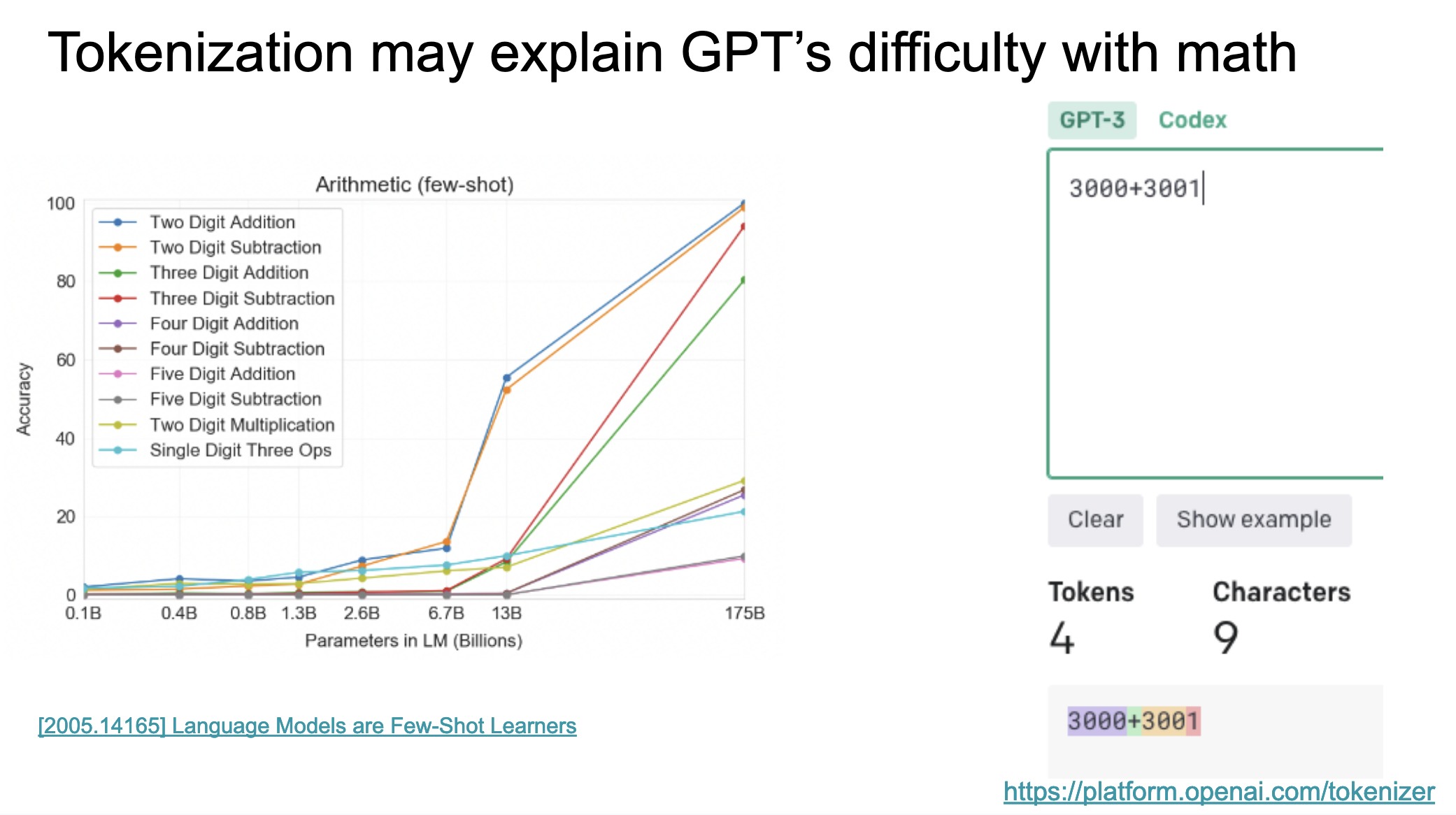 |
|---|
| GPT struggles with math |
As usual, Jay Alammar does an excellent job breaking this down.
More to come! I’m hoping to have more time to write now that I’m kind of a free agent :)
 Llama-2: Judgement Day
Llama-2: Judgement Day