Ben
Ben 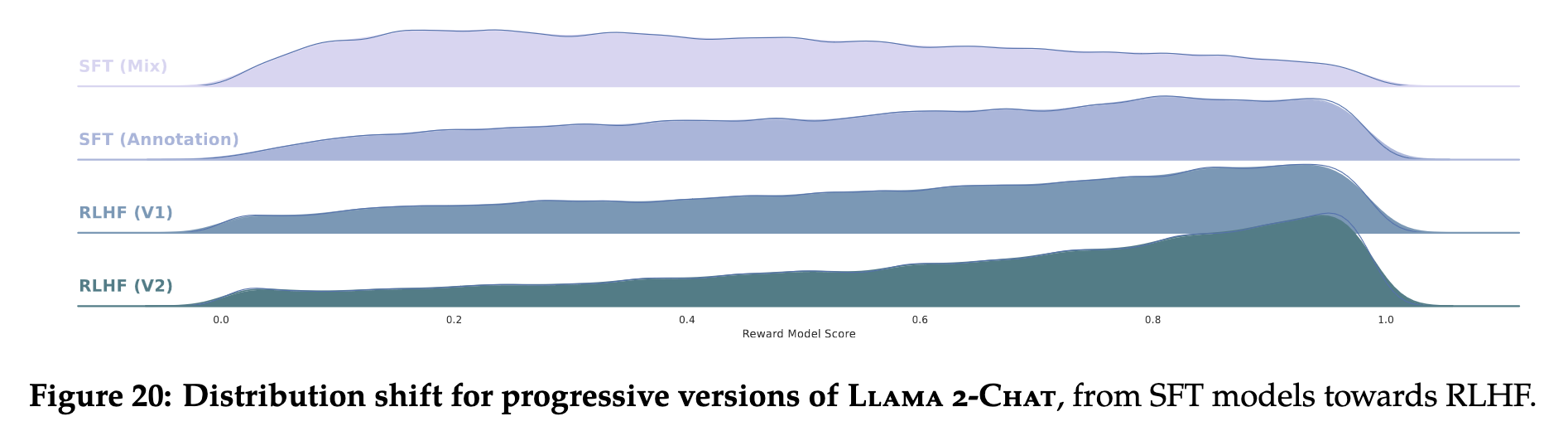
This is another paper summary, this time focusing on the Llama-2 paper
I did try using some combination of GPT + Claude here, but really struggled to get anything particularly useful from my outline. I welcome suggestions on how to make this work better, but so far, it’s ending up useful for me to just do my own work.
Llama-2 is a new Large Language Model (LLM) from Meta. It is an update to the original Llama-1, with the major changes being:
- A new training/pretraining corpus
- Doubled context length (4k vs 2k)
- Grouped-query attention (see below)
The new model outperforms or is closely comparable to top conversational models:
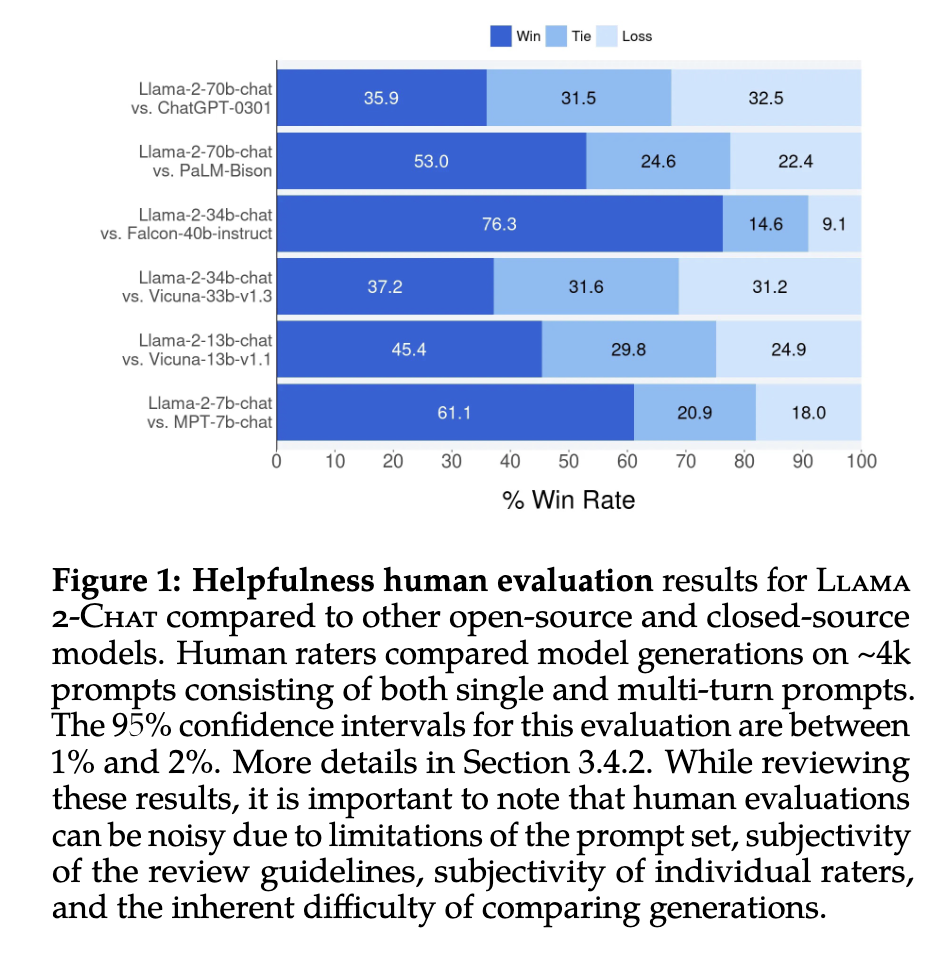 |
|---|
| Llama-2 model versus others source |
Pretraining
Pretraining, in this context, refers to the simple Language Model objective. That is, the model is trained to predict the next word, given the context. As mentioned in my LLM series, this is the kind of “autocomplete” objective. A lot of this is the same as the Llama-1 structure with the exception of:
Grouped-query attention
There’s an excellent walkthrough of multi-head attention that describes the process by which each token is given its own “representation” within every “head” of the attention layer. You can imagine this becomes very complex over a larger and larger sequence. Llama-2 introduces an optimization that “groups” some of these representations together to reduce the memory footprint and optimize throughput.
Two flavors of tuning
You’ll remember from my LLM series that LLM-powered assistants typically go through two types of tuning; instruction tuning and alignment tuning. This paper goes into (excruciating) detail about how these steps are done with Llama-2.
Supervised Fine-Tuning (SFT)
A dataset of prompts and responses is constructed based on public and vendor-sourced data. The authors go into detail here, describing how they find from sampling these data various errors and “unsafe” responses (i.e. responses that contain harmful information). They stress the importance of curation at this step. The paper details how the training proceeds, even providing some of the hyperparameters, which I found pretty unique for this type of paper.
Reinforcement Learning from Human Feedback (RLHF)
In this step, the authors took the interesting approach of aligning the model for both “helpfulness” and “safety”. Their example of the difference is the response to someone asking about making a bomb. “Helpful” would be to provide those instructions, as the intention of the model is to respond usefully. However, the useful response would not be considered “safe”, so the two sides could be considered almost in opposition. I’ll leave it to the ethicists to consider that point.
The paper details the annotation process, which I found really interesting. Annotators manually wrote a prompt and responses were sampled from the model using varying parameters. The annotators then rated which was more helpful and which was more safe. This model was updated as the weeks went on, so the annotators were always responding to the “freshest” model.
The “reward model” is trained to take an input and a response and basically do what the annotators do by hand; identify whether the response was helpful, safe or neither. Two separate models were trained to handle that “opposition” described above. These models are actually LLMs themselves, initialized from the base Llama checkpoints, though they are not trained to predict the next word, but rather predict a “class” (e.g. helpful/not helpful).
I won’t go into detail about RLHF here, I tried my hand at that previously. What appears to be novel here is that instead of the typical Proximal Policy Optimization (PPO) algorithm, they try an approach called Rejection Sampling Fine-Tuning. I’m not 100% on how this works, but the main point appears to be that it considers multiple responses from the model at once and goes with the best option, as opposed to just sampling one response.
And if you’re like me and complaining about all of a sudden having to learn RL, they have a visual that might be convincing:
 |
|---|
| SFT vs eras of RLHF source |
You can see here that the SFT-only model just generally underperforms compared to the SFT+RLHF model. And, with additional eras of training, the performance seems to improve. This seems sensible, the RLHF is generally tuned to do better with respect to the reward model. But to see it visualized in this way I found very compelling.
Safety dance
I want to spend the rest of the post looking at some of the author’s notes on including safety throughout their model training and evaluation. As mentioned above, they include measures of “safety” in each step:
- Pretraining - Evaluating the corpus for evidence of toxic language and representation of different gender/ethnic groups
- SFT - Inclusion of “safe” demonstration prompts in the corpus
- Safety RLHF - A (partially) separated workflow for aligning the model to generate “safe” prompts
One thing the authors found was that including more “safety” data in the model training vastly improved the model performance according to the safety scoring model, without harming the model performance on the helpfulness scoring model.
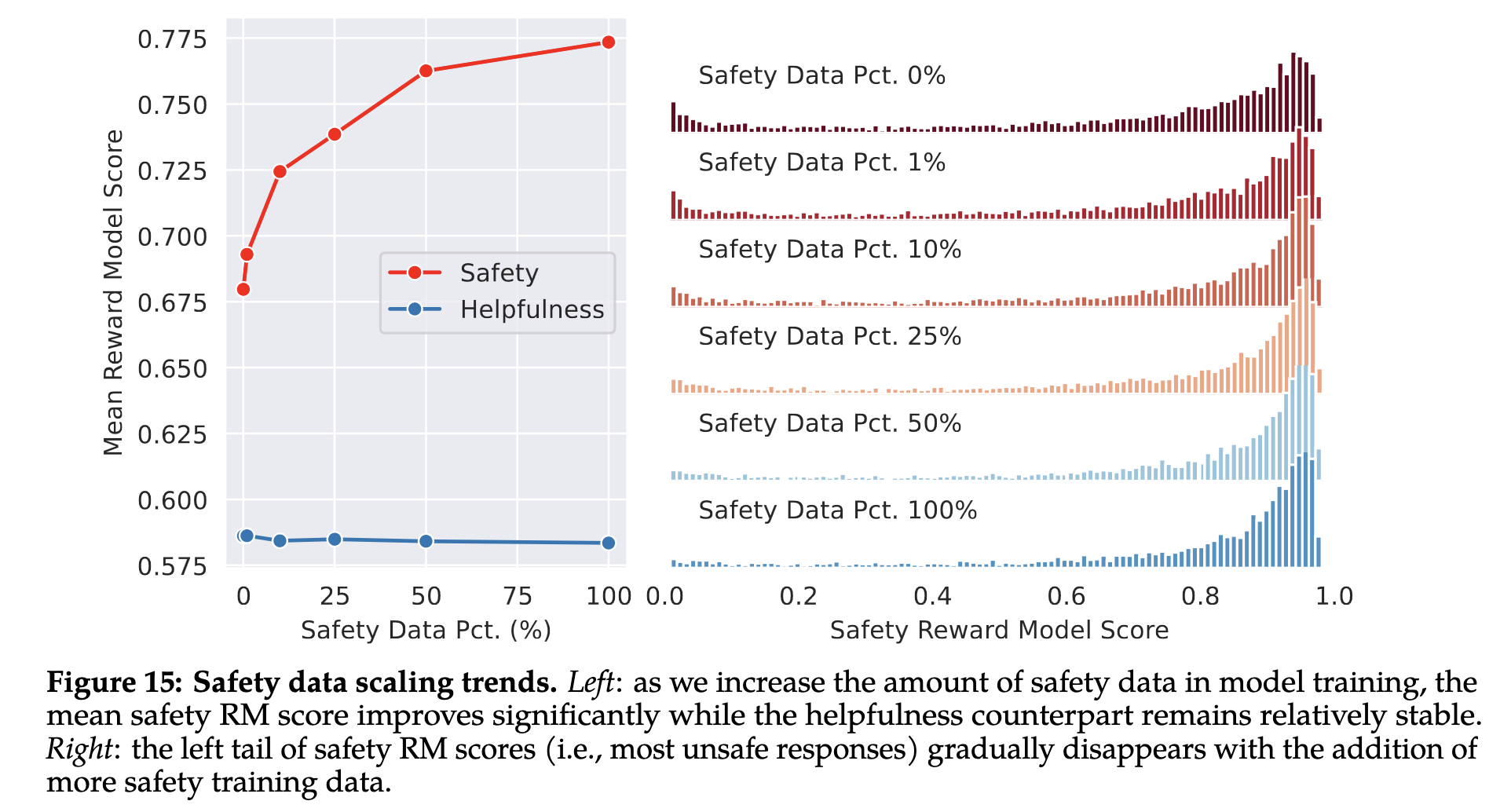 |
|---|
| Reward performance with increasing safety data source |
This suggests that providing a “helpful” response may not be that direct opposition to “safe responses.
Summing up
I think this paper is really fascinating and I will definitely be referring to it as I further my work in this area. Hopefully more papers follow this model; providing detailed overview of their process and in-depth analysis of the strength and potential weaknesses of the source corpora and the resulting models.
More to come!