 Ben
Ben 
Good news everyone! I’m going to be presenting again at ODSC East! This time I’m going to shift focus and really dig into Large Language Models (LLMs). Partly because everyone else is doing it and partly because I need a good motivator to really get myself familiar with the actual standing up of these systems.
In this post, I want to accomplish a couple things:
- Establish a rough framework for a “conversational LLM application”
- Build a minimal version this application
In later posts, I plan on expanding on this application using the wide variety of open and closed-source tools out there. In this way, I’m aiming not only get familiar with these tools, but also get a sense of where they fit in to the development of applications.
As always, it makes sense to break down what we mean by “LLM application”.
What is an LLM?
This, I think, I covered.
What is an application?
Gosh, isn’t this real philosophy here.
Definitions of applications are pretty unsatisfying here. Generally, anything that isn’t just a computer’s internal goings-on is an application. I’m going to make a lot of developers angry and say, simply, that an application has two components:
- Frontend - This is the user interface; everything the user sees and is able to interact with
- Backend - This is what carries out all the business of the application.
Think of the browser you’re using right now. Depending on which one you use, you can click the back button to go back a page, enter a new url, scroll, etc. That’s the interface, it receives your input. Now that input is translated, within the application, to some behavior via developer magic that, honestly, I don’t even fully understand. From input, to output.
Throwing an LLM into the works
What makes an LLM application different from other applications?
Groans and sighs from the audience as I answer: The LLM.
In my view, an LLM application is similar to any other AI application in that there’s a model that needs to be fit into the workflow. That means the application needs to make the user play nice with the model and vice versa. If we want to get philosophical, it’s input/output pairs all the way down, but to abstract a bit, let’s say the LLM application has a few components:
- Frontend - The user interface, as with other applications
- Input processor - Translate the user interaction into model input
- Model - In this case, the LLM itself or whatever service is hosting the LLM (e.g. OpenAI)
- Output processor - From model to user
Practically, what does this look like? Let’s take ChatGPT as an example:
- Frontend - The webpage itself, which prompts you for an input
- Input processor - The application takes the input and passes it to the model
- Model - GPT 3.5 or 4, depending on what your using, hosted in some intelligent way to not break OpenAI’s servers
- Output processor - The model produces an output and that is passed back into the chat interface
I know - this is simplistic, but it’s helpful for me to break this down because different technologies help with these different functions. For example, you may use OpenAI’s APIs, which provide you with a structure for providing input and processing output. So the API is basically JUST the model. While ChatGPT (the website) is the whole stack.
This framing makes sense to me and helps me categorize some of the technology out there. The all-powerful transformers library is mainly for processing and LLM components (through huggingface-hub). Gradio provides a lot of tools for building user interfaces (frontend). This categorization may be…loose, but it’s helpful for me.
One thing I’m leaving out here is the “conversational” piece. The key component of a chatbot is, say it with me: “chat”. And it wouldn’t be a conversation if there’s no memory of what’s been said.
Remember, remember
I wouldn’t exactly call the mechanism being used to store previous interactions “memory”, but it’s a useful short-hand. One very simple way to implement this is to just pass the entire conversation in the prompt. However, there’s a limit to how long the input can be (the length of the “context window”). One way ChatGPT gets around this limitation is using a Redis cache for interactions. Note - this is a bit old at this point, so I’m not quite sure this is how ChatGPT works these days. It’s difficult to know because, well, closed-source.
So let’s add this as a component to make our LLM stack “conversational”:
- Frontend - Similar to any other application
- Input processor - Translate the user interaction into model input
- Model - In this case, the LLM itself or whatever service is hosting the LLM (e.g. OpenAI)
- Memory - Context storage
- Output processor - From model to user
In the case of ChatGPT it’s memory is (maybe?) the Redis cache. It may be helpful to look at a diagram of the workflow for an LLM application versus a “chatbot”:
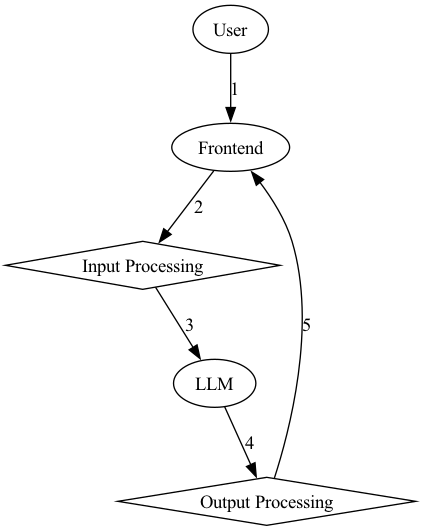
This is a very basic workflow - there’s no memory here, but there is the processing on both ends of the LLM.
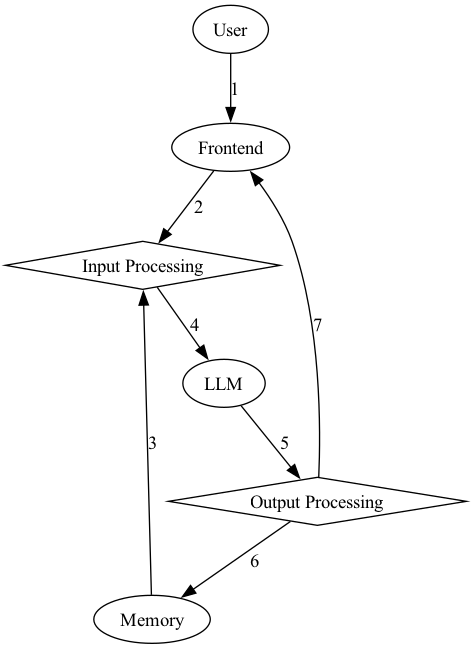
Now, with memory included, we have memory provided to the input processing (i.e. memory retrieval) and memory as a recipient of the output (i.e. memory storage).
This is all very simplified, but I find it useful to start from the basics and build from there.
SimpleBot
What does this all mean? I think the best way to explain is with an actual in-code example. To end this post, I want to build the simplest “working” example. Since I’ll be demoing a lot of this to the ODSC audience, I wanted to see if I could make something that is minimal, free, and shareable. So this simplest example will be a short Google Collaboratory notebook, requiring no(!) GPU. The model we’ll be using will be…somewhat stupid, but it’s code that can be easily edited to use a more sophisticated model. The purpose here is to get something that sets up the initial workflow and demonstrates the utility of a “memory” mechanism.
The notebook is here.
So how does this fit into the framework I set up above?
- Frontend - Collab notebook with a “raw_input” function
- Input processor - Transformers implementation of the model tokenizer
- Model - Meta’s OPT model, available on HuggingFace Hub and served via transformers library
- Memory - Stored as string, appended to input
- Output processor - Transformers de-tokenization
This works! Sort of. But it requires a bunch of hacking around in a notebook and with our collaboratory instance. In the next posts, we’ll build on this example, using some other LLM development technology to abstract away some components and enable us to build functionality onto our bot.
Stay tuned!
 Tokens to Transformers: An update to Bagging to BERT
Tokens to Transformers: An update to Bagging to BERT