Ben
Ben 
This is part 2 of my series on LLM applications. Check out part 1
Last time we built a simple conversational flow. It had the essential elements I laid out for a conversational LLM application:
- Frontend - The user interface, as with other applications
- Input processor - Translate the user interaction into model input
- Model - In this case, the LLM itself or whatever service is hosting the LLM (e.g. OpenAI)
- Memory - Context storage
- Output processor - From model to user
Our simple bot looked something like this:
- Frontend - Python notebook
- Input processor - Transformers implementation of the model tokenizer
- Model - Meta’s OPT model, available on HuggingFace Hub and served via transformers library
- Memory - Stored as string, appended to input
- Output processor - Transformers de-tokenization
So, all the elements. But there’s a few pretty major issues here:
- A notebook is just not a good fronend
- Our workflow is a while loop which is…not optimal
- Our memory mechanism will eventually break the bot when it overflows the maxmimum context length
Truth is - we don’t need to be coding everything from scratch. Smarter people (than me, at least!) have done a lot of work to abstract away some of the complexity. I want to review a few tools I’ve explored.
Ollama, where art thou?
Yes, these will all be puns.
Ollama is a tool for running LLMs locally, which takes the best of the open source optimization technologies (e.g. llama.cpp) and wraps it all in a nice little application. And yes, I mean a full application - by using Ollama in “run” mode, you basically have a fully-functional conversational LLM application.
Check out this notebook to try it out for yourself in a free CPU Collab instance.
To save you some time, here’s what the conversation we were having before looks like:
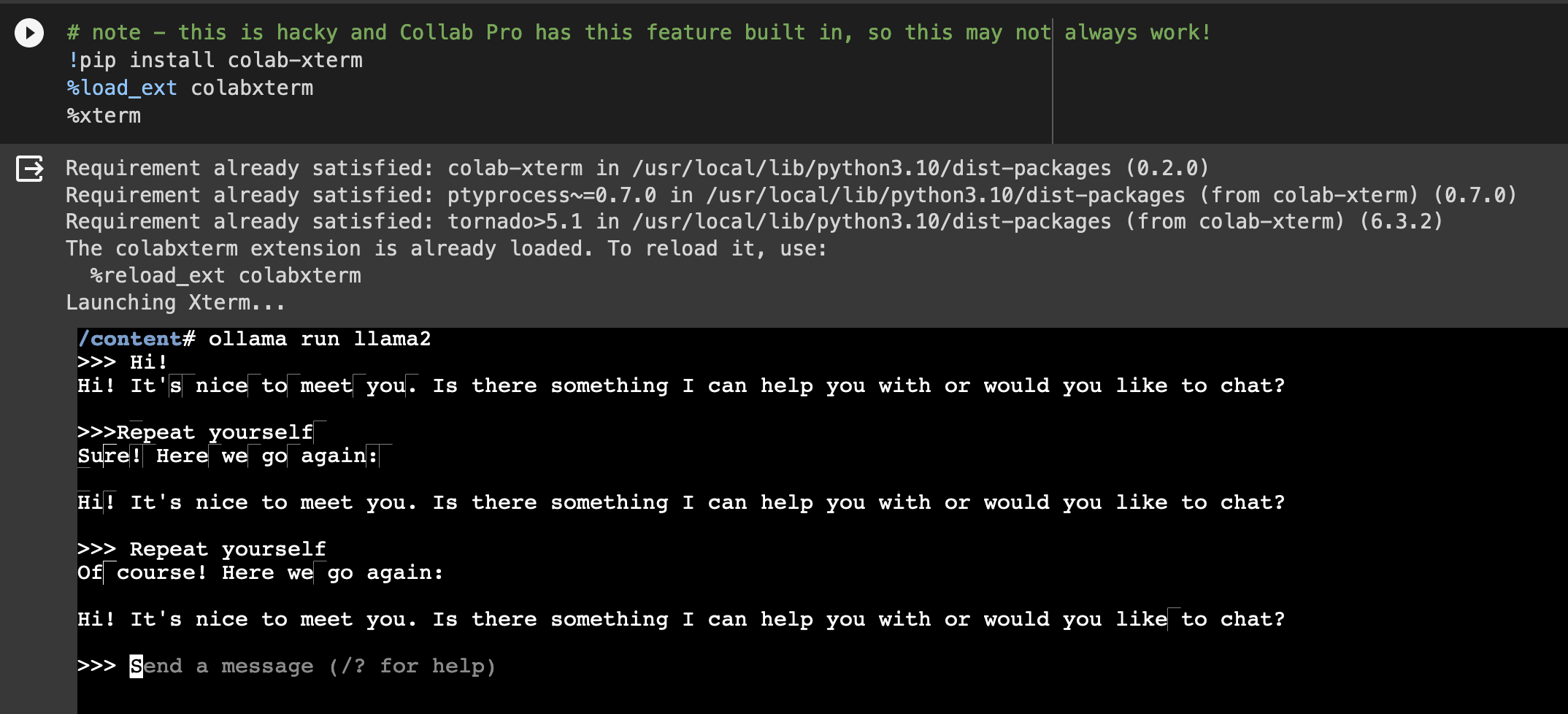
Interestingly, it’s not as good at following the direction to repeat itself as the smaller model. There’s lots of potential reasons for that, but generally LLM generation can be a bit hard to control. I’ll aim to explore that in a later post.
So what does the stack look like here?
- Frontend - Application running in terminal
- Input processor - Llama.cpp + Go code
- Model - Llama 2 7B Parameter Model
- Memory - Stored as list of token indexes (try verbose mode to see this)
- Output processor - Llama.cpp + Go code
To be honest, ollama run llama2 basically is everything we need. If the goal is just a simple chatbot, locally hosted, we’re all set. But Ollama’s run mode isn’t very customizeable, essentially all we’ve picked here in the model we want to run. In the notebook, I included a way to use Ollama’s API to communicate with the model using the requests library and using LangChain. LangChain I want to return to in a future post, but let’s move on to some other options out there for building applications.
With a name like Oobabooga it has to be good
Technically the name of the project is Text Generation Web UI. But I think Oobabooga (the repo owner) is more fun to say. Especially in a professional context.
Oobabooga is essentially a wrapper on top of some powerful Python libraries (e.g. transformers, Gradio, peft). Because it’s open-source, there are all kinds of add-ons and versions you can mess with, but we’ll just be using the base functionality (as available 11/2023).
Luckily for us, the repo already has a working example in Google Collab. This requires a GPU instance, I haven’t been able to get this working on CPU in Collab.
You can dig into the code a bit there, a lot of it is pretty straightforward. When you run the cell, it will take some time to spin up, but eventually you’ll get a link to the live application:

Note - this is PUBLIC! So not secured, this is fine for messing around, but don’t put anything sensitive in here.
The tab that will open when you access the link should be named “Chat” and the interface should look very familiar if you’ve toyed with a chatbot before. Our conversation proceeds as expected:
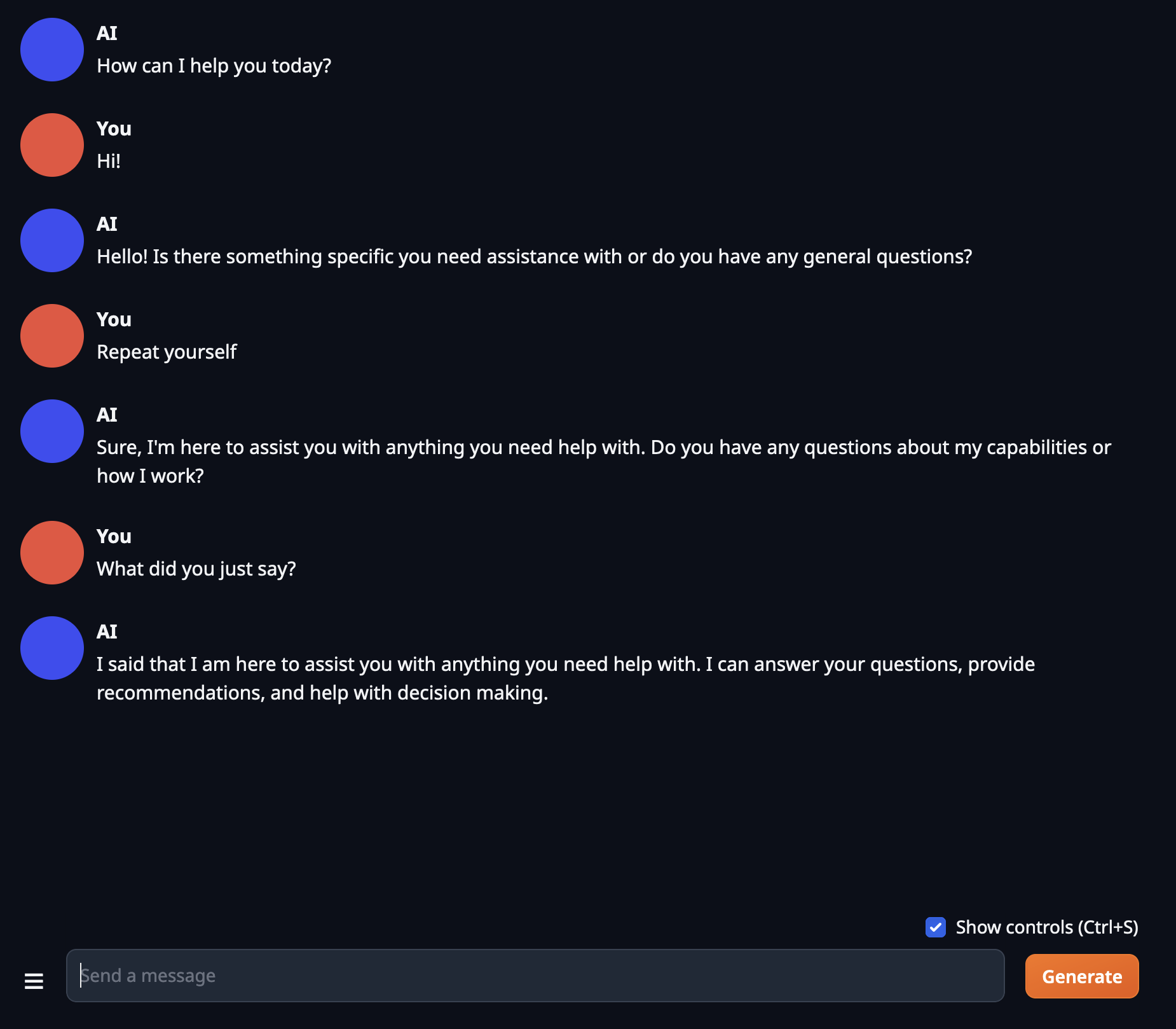
Again it doesn’t exactly follow directions when asked to repeat itself. But, it still seems to demonstrate it has contextual information (i.e. “memory). The memory capability is implemented as a element of Gradio state for the user’s session. I’m not 100% how that works - I don’t have a lot of experience with Gradio. But it provides functionality for maintaining things like the history of the conversation.
The resulting stack looks something like this:
- Frontend - Gradio
- Input processor - Transformers, model loading libraries (e.g. ExLlamaV2), Gradio
- Model - Mistral 7B instruct model
- Memory - Managed in the Gradio state
- Output processor - Transformers, model loading libraries (e.g. ExLlamaV2), Gradio
Among the many things maintained within the session “state” are various aspects of WHO this assistant is. You can take a look at the Parameters tab and check out “Character” and “Instruction template”. These govern what is actually being passed to the model. By changing some of these parameters, you get very different results.
The base implementation here has another character under “Example”. This character is…painfully anime. Experiment with it and notice some of the differences. This all gets into the concepts of “system” and “user” prompts - which maybe is its own post. If you want to get ahead of me, here’s a good intro to these concepts.
One other thing I want to tee up for later is the “Training” tab. This actually gives you the ability to tune the model based on your own data, all within the application. Again, let’s talk about this another time, but I wanted to point it out for you enterprising readers.
In general - Oobabooga is a good tool for experimentation. It does a lot of things, but as a result is heavier weight and requires more configuration. Ollama is a bit more straightforward - all it’s doing is giving you easy access to generation. If you want to do more, you’ll need to go outside of Ollama.
Think of Oobabooga as an Instapot and Ollama as one of those basic rice cookers. Instapot does everything, your homework, whatever. But if you’re planning on just cooking rice…maybe Ollama chat is enough.
One last interesting tool I want to introduce you to is LlamaBot, developed by my colleague and fellow data nerd Eric Ma.
LlamaBot rolls out
LlamaBot is a way to make interacting with LLMs more “pythonic”. What does “pythonic” mean? Essentially, it means it fits better with the Python language. Try import this in your Python console to get some of the tenets of the language. These are kind of rough guidelines for developing in Python. But from my read - it just means LlamaBot provides some consistent syntax for some essential LLM use-cases. You might think of this as a nice intermediate between Ollama as an API for interacting with LLMs and Oobabooga as a fully-functional LLM experimentation platform.
LlamaBot supports both OpenAI and Ollama, leveraging LangChain for the chatbot “structure”, but with its own dressing to enable consistent syntax. In this notebook we essentially repeat the same setup as with the other tools. You’ll see that LlamaBot has its own ChatBot class, which maintains a history as a list of input and output. We also are required to provide it with a “character”, which I adapted from the default Oobabooga assistant. Try it out in the notebook.
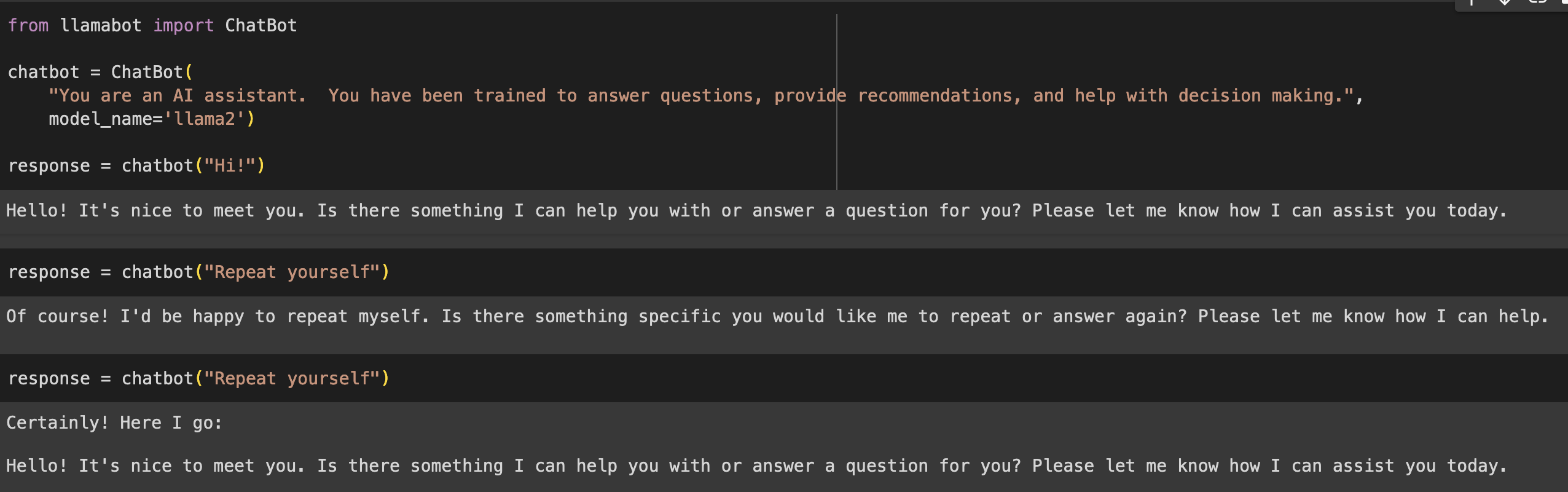
You’d imagine the response would be the same as with Ollama’s own chatbot setup, but there’s a different set of parameters provided by default here. However, we still see it demonstrating some kind of “memory”. The stack looks something like this:
- Frontend - Python notebook
- Input processor - LangChain plus custom code
- Model - Mistral 7B instruct model
- Memory - Stored as list within the bot instance
- Output processor - LangChain plus custom code
There’s more functionality to LlamaBot we’ll get to when we talk about including information from a document store. The repo has a bunch of examples to that end, if you want to jump ahead.
But, like, which is the BEST
This overview is by no means comprehensive. There’s daily new technology coming out there. And, honestly, I don’t really know which tool to recommend getting familiar with because I’m still trying to grok the systems and the use cases. But from what I can tell, these three tools offer very different things.
Here’s a couple functions I feel might be important:
- Full stack - Does the tool offer the full conversational LLM chatbot stack?
- Multiple bots - Does the tool offer multiple “bot” designs (e.g. chatbot, document query)
- New models - Does the tool provide methods for installing new models
- Fine-tuning - Does the tool provide methods for fine-tuning your model
- API integrations - Does the tool integrate with other APIs (e.g. OpenAI)
These are useful, but also they, I think, capture the differences between the tools:
| Function | Ollama | Oobabooga | LlamaBot |
|---|---|---|---|
| Full stack | Yes | Yes | No |
| Multiple bots | No | No* | Yes |
| New models | Yes | Yes | No |
| Fine-tuning | No | Yes | No |
| API integration | No | No | Yes |
*: This is the current version (11/2023) - there’s a bunch of add-ons available, though
One thing I want to point out - I recognize that the input and ouput components of all the tools I listed are basically the same. But that is not ALWAYS the case. When does it vary? Well, maybe your want to augment your input with something you retrieved from elsewhere. Some kind of Retrieval Augmented Generation.
Tune in next time for part 3 - RAGs to riches. It’s probably the best pun of the series.
 LLM Apps Part 1 - Coding from scratch
LLM Apps Part 1 - Coding from scratch