 Ben
Ben Hi folks! I’m going to start a series documenting my progress through the Stanford CS230 course. The course is meant to go alongside the Coursera Deeplearning.ai materials, but right now I’m going through the lectures from CS230.
I’ve been through some of this material before, but I find myself forgetting most of it if I don’t take notes. I figured an even better exercise would be to write blog posts based on those notes. Ostensibly, that’ll help me remember it better. But, in the worst case, at least I’ll have a few interesting posts.
So here’s some of the course info, I’ll attach this to all my posts just to keep it consistent. Any images or material described below is taken from the course materials unless otherwise noted:
Stanford CS230 course Lecture 1: Introduction video Lecture 1: Introduction slides
In this lecture, Andrew Ng takes us through an overview of the course purpose and generally the promise of Deep Learning as he sees it. He starts by specifying the use case for something like a Deep Learning model. That is, it is most useful in circumstances with a large amount of data is available.
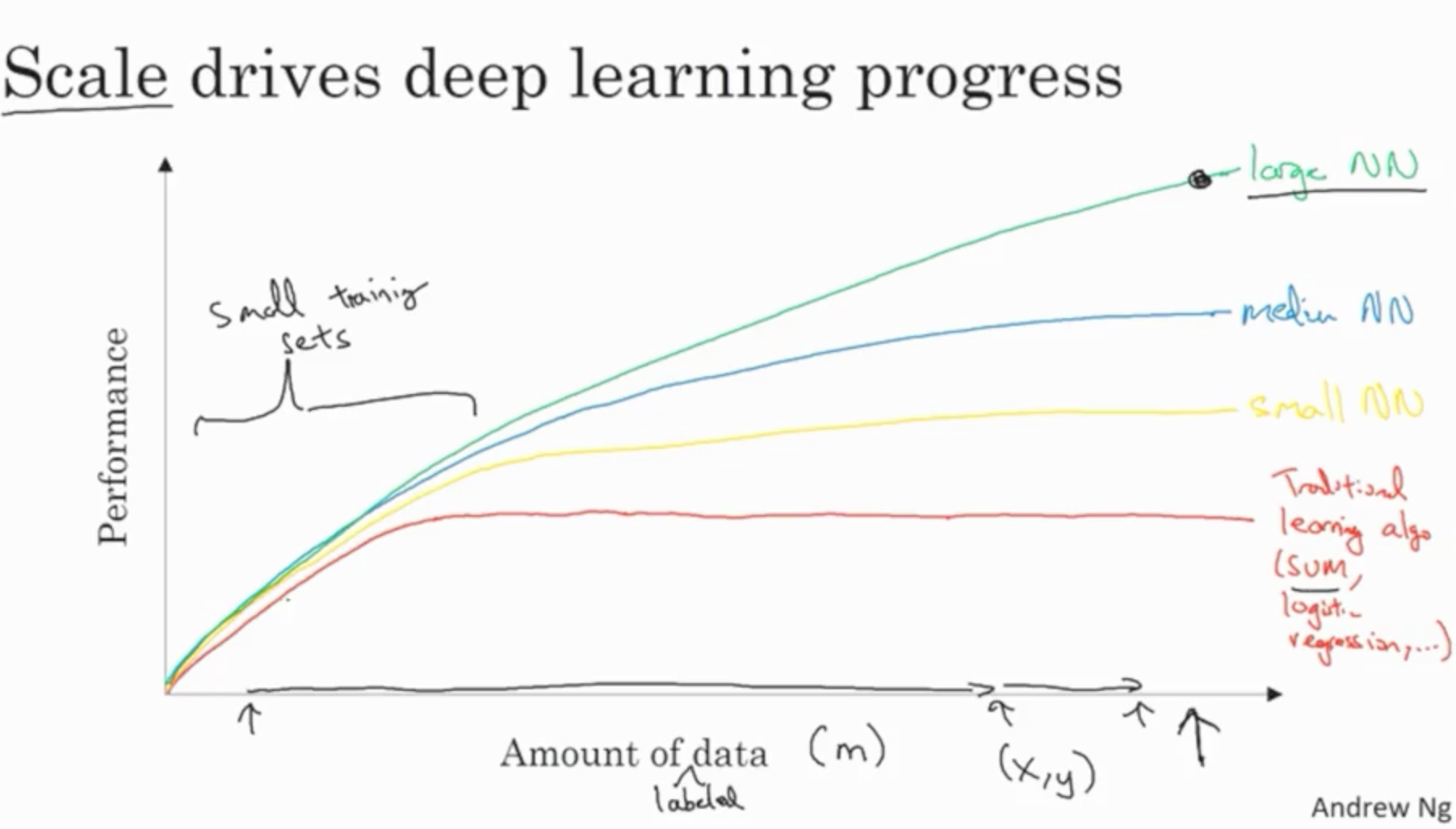
It’s an important point. I’ve definitely found that parametric or generally “shallow” approaches are comparable to neural nets in a lot of my small-data usecases.
These performance gains are pretty substantial. He explains that the field of Deep Learning and Machine Learning is particular popular right now because it seems like new innovations that drastically improve performance are coming out on a regular basis. He compares DL/ML to areas like Probabilistic Graphical Models and Knowledge Graphs.
The purpose of the course are, roughly, to give an overview of the field and the considerations of building Deep Learning models. Additionally, the course aims to provide a sort of systematic way of thinking about building and implementing these models. He goes on to explain why this is particularly important to think about by giving an anecdote from his own experience.
He describes a shopping mall as not being an internet company just because it has a website from which people can purchase products. Particularly, he points out three main differences:
- A shopping mall isn’t able to do A/B testing. The mall itself is a standard experience and one that’s fairly difficult to change. Particularly, it’s impossible to change the experience for some visitors and not for others.
- Relatedly, an internet company has short development cycles. Changes to a shopping mall take a lot of time. For a company like Amazon, they could implement a change overnight.
- Long development cycles for shopping malls mean that if every change has to be run by the CEO, that’s not really a problem. For an internet company, most of the decisions on changes are made by engineers and product managers.
He explains that it follows that just because a company uses neural networks doesn’t mean it is an AI company. That there are a lot of design differences that differentiate a company using Neural Networks from a company that has AI as part of its philosophy. Particularly, he points out some differences:
- AI companies (like Google) tend to spend time and resources gaining data that will be useful to algorithms
- AI companies tend to have a unified data warehouse
- AI companies also are focused on opportunities for automation
As I understood this comparison, Andrew is pointing out that it’s not enough to just be plopping a model down into a problem. To effectively leverage the promise of AI, companies need to see the whole picture. That means thinking about the data feeding a model and where the outputs of that model fit into the general process of the company.
Super interesting lecture! See you next time.