 Ben
Ben Annnnd we’re back with more overviews of talks from the spaCy IRL conference. This time Sofie Van Landeghem takes us through the work-in-progress Entity-Linking model in spaCy.
So you may have heard of Named-Entity Recognition (NER), where a model is trained to identify “real-world” object in text (e.g. people, places, companies). That’s all well and good, but what if multiple entities have the same name? Sofie gives the example of Lord Byron, Lady Byron and Ada Lovelace (their daughter). One text may refer to any one of them as “Byron”. The NER model might be able to identify that Byron is a named entity, but identifying WHICH Byron is a whole different story. And model.
Actually linking a named entity to its real-world information is called Named-Entity Linking (NEL). This is a complex task because not only do you have the issue of Byron referring to multiple people (Polysemy) but you might have one person with multiple titles (e.g. Ada Lovelace is also referred to as Ada Byron) (Synonymy).
To develop the NEL model at spaCy Sofie and the spaCy team made use of WikiData and Wikipedia. Wikipedia has an extensive list of aliases for a particular named entity.

Wikidata provides the links between Wikipedia pages which allows for linkage across languages. It also provides some short descriptions of what the entity is, which is useful for the model embeddings.
The framework of NEL with spaCy is to combine the results of an NER model (i.e. the identified instances of a named entity) and use those identified entities to create a list of linkable candidates. For example, if NER identifies the name “Byron” as a person, those instances are then fed to the NEL model, which generates a list of candidates based on that instance. It is then the NEL model’s job to identify which candidate is the correct one based on contextual information and the candidates’ descriptions.
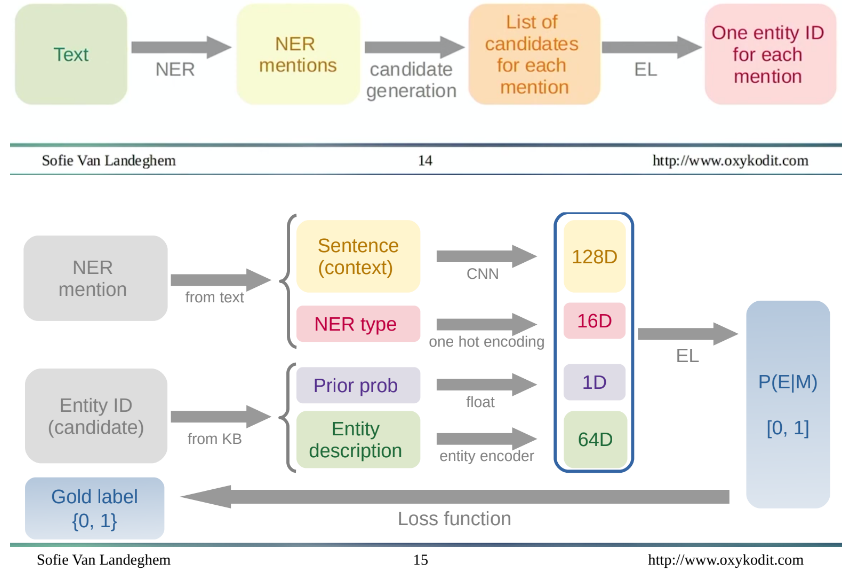
I basically put the whole visual here because I think it’s pretty clearly laid out. The NER model outputs the context encoding, the NER type and the Knowledge Base outputs information from candidates (i.e. descriptions and how likely there is a link between a particular named entity and that candidate). All this information gets passed to the NEL model, which determines which candidate is correct.
Sofie dives into even more technical detail, outlining how the model is implemented, which you can see in the slides.
The results of using this model indicate that most of its power comes from just having information about how likely a mention is to be about a particular candidate (i.e. the “Prior Prob” in the above visual). But the additional contextual information did end up being marginally useful in linking.
The next steps for the model are to improve the data sources and include co-reference information. For improving the data source, Sofie points out that there were several instances of the Wikidata description being missing or the gold standard labels being incorrect. Additionally, Wikidata apparently also has a Knowledge Graph available, which would likely boost performance in a model like this one.
As for co-references, text often mentions a particular entity multiple times and being able to disambiguate these references and feed their context as features to the model would likely be very useful for linking.
I found this talk really interesting and it did a great job of covering the project from problem statement to implementation to evaluation. I’m doing a lot of work with NER right now and likely I’ll have to consider linking tasks in the future.
Till next time!