 Ben
Ben As I mentioned last time, I’m going to start digging into some topics of interest to me and put together my notes in blog form. My main purpose here is to keep an inventory of the topics I research, but I hope these posts are useful to others. I’d also be eager to discuss some of this with anyone interested in talking more.
I first intend to pick a few talks from the recent spaCy IRL conference that took place in July and summarize some of the key points. This week I start with Sebastian Ruder from DeepMind and his exploration of Transfer Learning. Let’s go!
Just a quick background: Sebastian is an excellent writer and expert on the subject of NLP. I’ve read several of his articles giving overviews of important NLP-related conferences and been really impressed by the level of detail. He’s also covered Transfer Learning in NLP before at NAACL and his tutorial slides are here.
Transfer learning, as Sebastian defines it, is where you borrow learnings from task A (e.g. identifying the language used in text to bring to task B (e.g. classifying whether text is positive or negative). This is particularly relevant for NLP as language has a shared structure. That is, even if a text corpus comes from a different source, it’s still likely to adhere to a similar structure (e.g. a sentence is likely to have nouns, verbs, etc). It’s also particularly useful to use transfer learning as finding labelled datasets is one of the key limitations of Machine Learning generally.
Sebastian presents the following visual to outline the different branches of transfer learning:
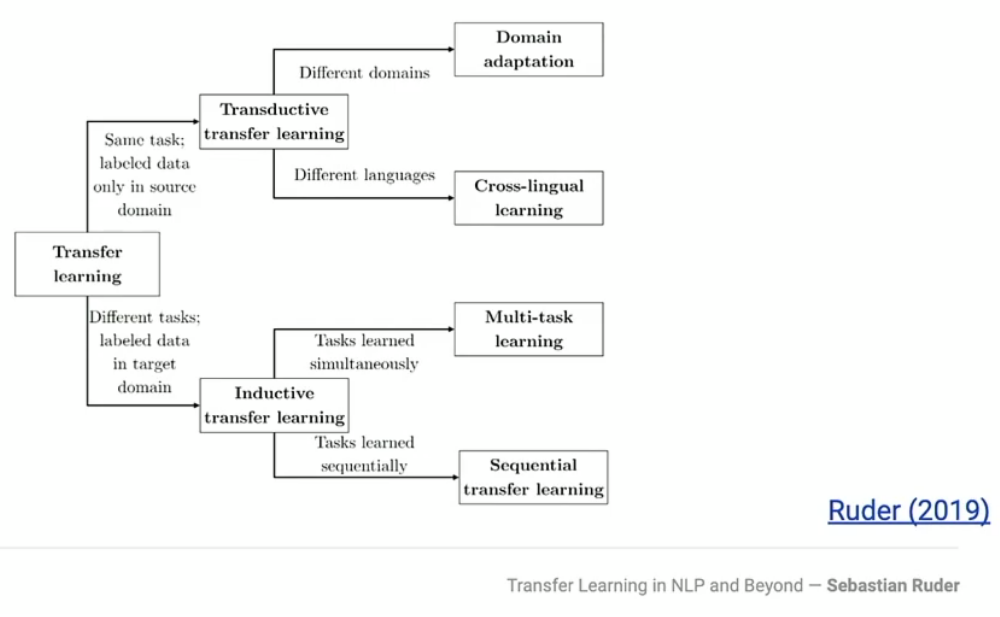
So in terms of tasks, let’s think about classifying positive or negative sentiment. If you’re taking a model trained on sentiment classification from one domain (e.g. Movie reviews) and applying it to another (e.g. A selection of Tweets), that would fall under Domain Adaptation. If you’re instead taking that sentiment model that has been trained on English text and adapting it to French, you’re in the area of Cross-Lingual learning.
Now, say you’re using that same sentiment classification model, but you’re going to use it (or some part of it) for language identification. These are different tasks, so they belong in the lower branch of the diagram. If you’re training both of these models simultaneously and somehow connecting learnings from each as part of the training (e.g. general language structure), you’re dealing with Multi-task learning. If you’re training the sentiment model and then using some part of that to then apply to the language identification task, you’re dealing with Sequential transfer learning.
Sebastian focuses on Sequential transfer learning for the rest of the talk, which deals with things like word2vec and BERT.
In this domain of sequential transfer learning, Sebastian outlines five major: Words to words-in-context Word vectors -> sentence/doc vectors -> word-in-context vectors (words in different context, different representation Language model pretraining Predict next word given the context In this case, you don’t need labelled/annotated text, it’s self-supervised This works because with enough data and a large enough model, it becomes possible to compress essentially any context into a generalized vector Pretraining vs target task In choosing the pretraining method, you want to ensure there’s going to be some similarity between it and the target task For example, doing sentence/document-level representations as pretraining for a word level prediction task probably doesn’t make sense Shallow to deep Generally, there’s been a move towards adding more layers to these neural models as this tends to result in performance gains However, this also leads to hugely expensive training processes
Regarding that last point, Sebastian takes some time to talk about the options available to access pretrained models and thus save yourself the headache (and time!) of training your own. He mentions several categories of resources and examples: Hubs: TensorFlow Hub, PyTorch Hub Author-related checkpoints: BERT, GPT Third-party libraries: AllenNLP, fast.ai, HuggingFace Where Hubs are very easy to access and implement, they give you limited access to the model internals. On the other hand, checkpoints give you more access, but are harder to implement.
Sebastian concludes the talk with some future directions for transfer learning. Many of the existing language models depend on the task of predicting the next word, but this doesn’t necessarily work well in summarization tasks, where there is a bunch of information from previous paragraphs/sentences that needs to be considered.
Additionally, many models do this prediction from left to right, which works well in English, but in languages like Chinese or in use-cases where the context to the right is important, that information is not being utilized effectively. Sebastian mentions that NLP might learn from the image domain, where models may be trained by being given a “patch” of an image and being asked to predict the rest. This would also move models to away from being limited to just next-word prediction.
Finally, there is limited use of semantic information in some of these models, as they’ve become very focused on this next-word prediction task. Sebastian advocates for thinking about how distances between words changes their relationship and how to incorporate this type of semantic information in models.