 Ben
Ben What’s missing in Natural Language Processing
I wanted to put out a quick one of these summaries as I’m working on a more extensive summary of a recent article on Transfer Learning in NLP. More to come on that. In this summary I took a look at Yoav Goldberg’s spaCy IRL talk on what’s missing in NLP.
Yoav opens with what I find is a really interesting visual on the history of NLP and the strengths/weaknesses of existing methods:
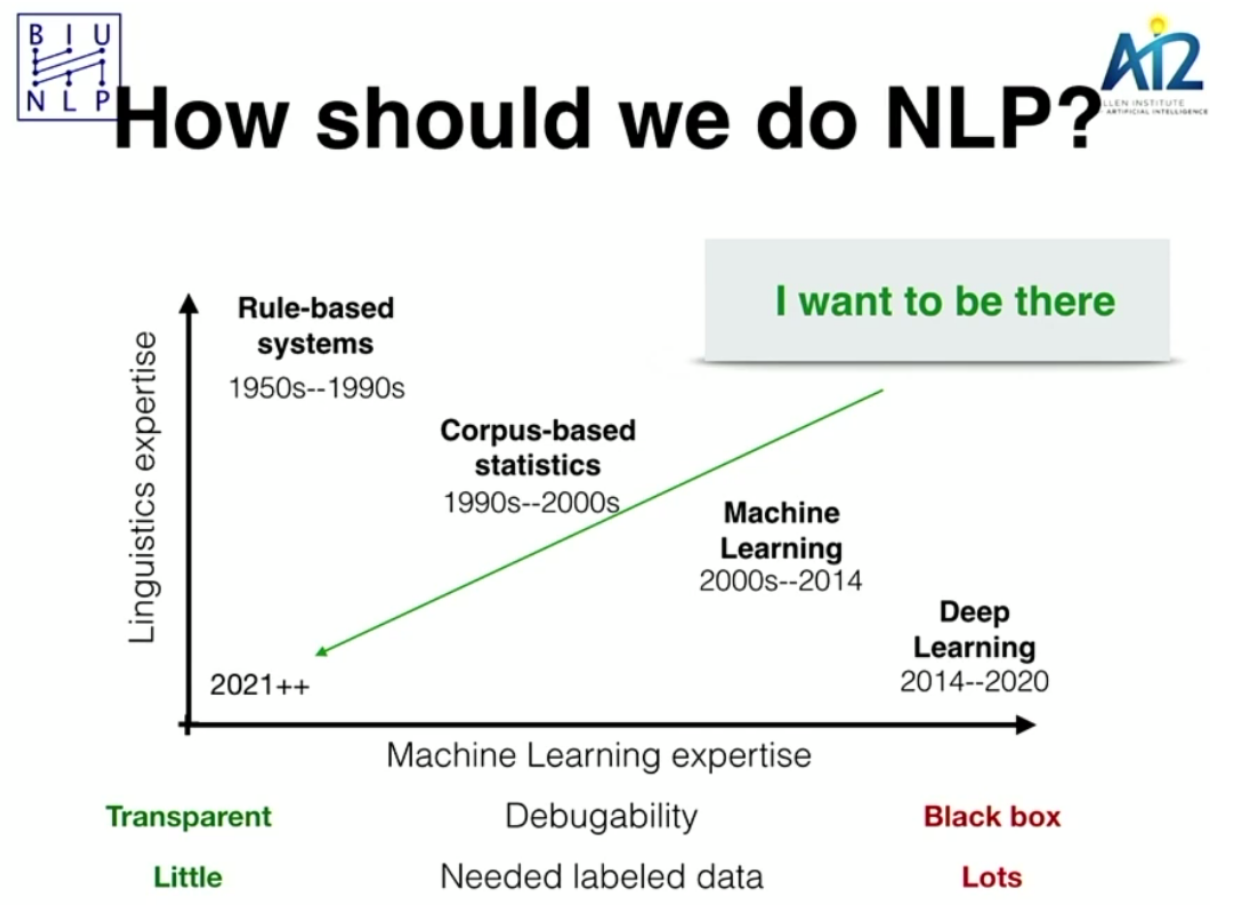
I thought this was interesting because it outlines the general movement of the field and what may be missed by intense focus on ML/DL, namely that we don’t have a lot of transparency and have to rely on pretrained models to alleviate the need for large datasets and long training times. I’m not sure I agree that we want to target low expertise. Honestly, the gaps Yoav points out seem like they require more leveraging of linguistics expertise in modern NLP.
Here’s the gaps Yoav sees, as I understood them:
1) Understanding what DL is actually learning and what it’s capable of learning
This was Yoav’s “Step -1” point, meaning it’s something we should try and understand before throwing ourselves fully at DL for NLP. In some cases, DL is not always the answer and we should think about what we’re trying to accomplish and whether DL models are the right approach.
2) Fairness and accountability
Yoav made this point a couple of times; we need to be aware of bias in models. There’s examples of sexism in the widely used word vector models and evidence that the techniques we’re using to reduce this bias may not be enough. A high-level gap, but an important once.
3) Extending NLP techniques to domains with limited data resources
As you can see from the visual at the top, some of the more advanced techniques require a lot of labelled data. Yoav proposes using matching rules plus syntax knowledge to turn large amounts of unlabelled data into more processed/labelled data. He uses as an example the task of identifying “John met Mary” in text. You could set a simple rule to match exactly those words or you could enhance it by trying to find any sentence in which “John” and “Mary” are proper nouns connected with a verb. That way even if the sentence is “John meets Mary” or “John will be meeting Mary”, you’d still have a match.
However, Yoav points out that “The meeting of John and Mary” would not be caught. So these rule-based approaches are difficult to develop and generalize.
4) Handling missing elements in language
Yoav dives deep here into a set of challenges that advanced NLP methods aren’t able to handle. One of the major ones is handling what he refers to as “gaps” or “missing elements”. For example, “May is a great programmer but John isn’t”. We know, from reading this that it means John isn’t a great programmer. But for a model, it’s hard for it to recognize what the “isn’t” is referring to.
Relatedly, with things like numbers, often in natural language we don’t repeatedly refer to an object when it goes without saying what we’re referencing. For example: “I ordered four cakes but only received three”. We, as natural language speakers, know that the “three” refers to a number of cakes, but for a model it’s tricky. So being able to understand the unwritten “cakes” after “three” is a challenging task for modern models and one that they tend to perform poorly at.
5) Beyond one-shot model development
I really like Yoav’s point here; models should not just be developed once and then never touched again. We should be able to incorporate expert knowledge into the models to be able to deal with some of the gaps outlined above. And that will likely improve any model, even the most advanced BERT/RoBERT/other Sesame Street character model.
Just to conclude: I think Yoav here makes a really strong point for more incorporation of understanding of language structure into model development. I don’t imagine the goal should be to reduce the expertise required, but better incorporate the available expertise into models. In my work, I have a lot of very smart people around me, but they either don’t have time or expertise to participate in NLP model development. However, if there’s some way to bridge their expertise and my expertise, then we get the potential to develop really powerful solutions.
I think Yoav makes this point, too. I just think the idea of “linguistics expertise” could be broadened to “language expertise” and be the target for incorporation into advanced DL models in NLP.
More to come!