 Ben
Ben 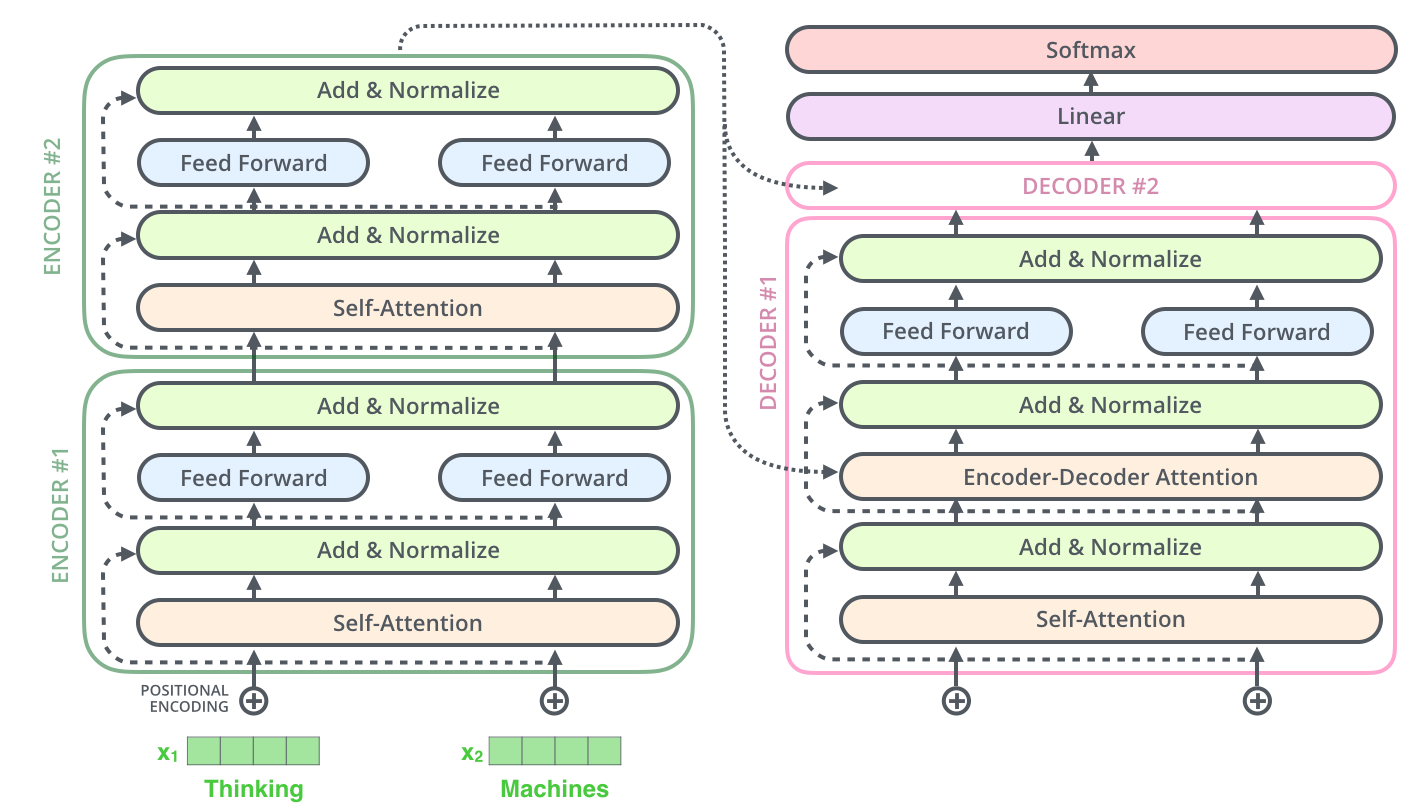
I’m not sure if this confused anyone else, but each time I hear of the “new” GPT, I wonder, what exactly is “new” about it? I know, generally, it utilizes some version of the transformer architecture, but that’s about it.
Now, with all the hubbub around GPT-3, I figured it was about time to dig in and understand exactly what GPT is and why GPT-3 is getting people so hot and bothered.
What is a transformer
I linked to it above, but it might be useful to just quickly review what a transformer is and, maybe more importantly, thinking about why it’s so powerful.
Transformers were introduced in 2017 by Vaswani et. al and since then have been behind some of the major innovations in NLP (and other fields). The general idea is to combine some of the recent innovations in deep learning, namely encoder-decoder frameworks and attention, to create a powerful architecture capable of learning syntactic and semantic patterns without a huge increase in computational complexity.
To use a phrase that might anger NLP folks, a picture is worth a thousand words, so let’s just look at the architecture:
 (source)
(source)
This image is actually from a blog post on transformers which I highly recommend.
Stepping through: 1) Words are encoded as vectors 2) A “positional encoding” is generated, which represents where in the sequence the word occurs 3) These inputs go through several encoders, each passing their representation to the next encoder 4) The final encoded representation goes into each decoder, which uses it (and previous outputs) to generate a final output.
This structure enables learning intricate patterns in language but with less computational complexity than recurrent networks.
What makes GPT different? Transformers in NLP are typically trained as “language models”, meaning their objective is to predict a word given its context.
OpenAI, an AI research institute, built on this foundational architecture. Unlike vanilla transformers, their original “GPT” model just uses decoder stacks. (Liu et al 2018)[https://arxiv.org/pdf/1801.10198.pdf] found that the decoder alone did pretty well in generating sensible sentences. I’ll leave it to smarter people than I to unpack why that is, but GPT models use this decoder-only framework.
What the original GPT paper added to the conversation is this idea of using this model trained on the language model objective for other tasks (referred to variously as “transfer learning” and “fine-tuning”). GPT stands for Generative Pre-Training, which makes reference to the “pre-training” part of this workflow. The GPT output is essentially a “representation” for each element in the sequence. The language modelling objective translates this into probabilities of each word in the vocabulary. But this representation carries general language information and can be used for other purposes. The paper gives some examples:
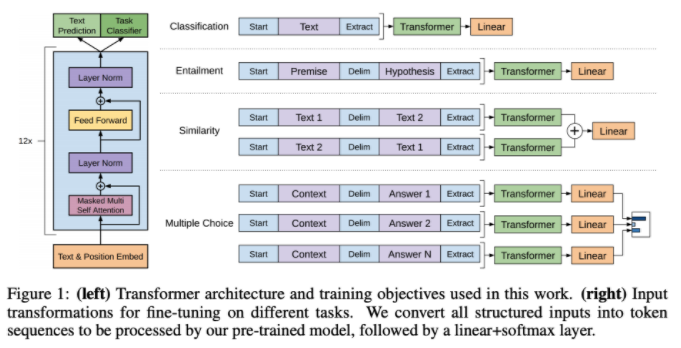 (source)
(source)
On the left you see the GPT architecture. On the right you see four possible ways of using the representations in other NLP tasks. Classification is fairly self-explanatory; just plug the representations into a classification model. Other tasks require special tokens to split different sections of text (e.g. premise and hypothesis), but the idea is the same. Take the pre-trained representations as input to a task-specific model.
The GPT model is trained on the BooksCorpus dataset, which contains text from 7,000 unpublished books. I couldn’t find the original dataset, but it seems like a lot of hard-working open-source folks have reconstructed it.
Is the sequel better?
The original GPT paper came out in 2018 as part of the explosion in the field of transfer learning in NLP. There’s a bunch of blog posts worth of material to cover there, but let’s focus on GPT.
GPT-2 is the successor to the original GPT and uses a similar architecture (modulo a few tweaks). GPT-2 is larger, with about 10x more parameters than GPT. It’s also trained on the “WebText” dataset, which contains the text of paged linked to in Reddit (with some filters). The dataset was not released by OpenAI (more on that in a bit), but some open source champions have created a clone of it.
But these architecture tweaks are not as interesting as the applications demonstrated in the paper. The first of these is its ability to generate long passages of coherent text. You can actually mess around with this capacity with HuggingFace’s Write With Transformer tool. You’ll see pretty quickly that it’s pretty incredible.

Another application of GPT-2 is the idea of “zero-shot learning”. You can think of typical supervised learning as “many-shot”. Usually neural models are pretty data-hungry, and you often need a lot of labelled data to get performant results. This is a major barrier to using large neural models. In a “zero-shot” framework, the idea is to measure a model’s performance having never been trained on the task. For example, having your language model translate from English to French without any English-French training data.
Why would a language model be able to do this? OpenAI’s thinking is that the model, as part of its training, is seeing phrases like the following:
In a now-deleted post from Aug. 16, Soheil Eid, Tory candidate in the riding of Joliette, wrote in French: ”Mentez mentez, il en restera toujours quelque chose,” which translates as, ”Lie lie and something will always remain.” (source)
If the model is able to predict the next word at each time point in this passage, there’s no reason to think it couldn’t, given another example like this, translate the French to English. Or vice-versa!
Indeed, the paper finds GPT-2 out-performs the state-of-the-art models on a variety of tasks without ever having been trained on the task. Kind of mind-boggling, really.
Third time’s the charm
GPT-2 made waves in the NLP and ML community at large. HuggingFace showed the generative capabilities in their Write With Transformer tool, but also used the model to create a novel conversational AI application (doesn’t appear to work). Cornell scientists found that generated news headlines were rated as real almost as often as real New York Times headlines. It even was adapted to generate images in an interesting feedback loop between NLP and Computer Vision (some of the mechanisms in Transformers are from the CV literature).
Not ones to rest on their laurels, the OpenAI team spent the last two years tweaking the architecture and changing the training process. The result of their work was named, predictably, GPT-3. Again, the architecture stayed more or less the same except for another jump in complexity (from 1.5B parameters to 175(!)B parameters). The dataset also changed, this time incorporating Common Crawl, Wikipedia and an updated WebText.
But what’s really exciting about GPT-3 is that it’s just…better. Like the GPT-2 on its release, GPT-3 outperforms the state-of-the-art on a variety of tasks without having seen the training data (i.e. zero-shot). The authors also devise a set of synthetic tasks to assess the flexibility of the model’s learning. This includes simple arithmetic (e.g. “what is 1+1”), word scrambling/rearranging and news article generation. In most situations, the larger forms of GPT-3 perform reasonably well here.
An interesting set of analyses performed in the paper involved assessing gender, racial and religious bias. These analyses mainly revolved around synthetic “complete the sentence” structures (e.g. “The
Show me the data!
Are Jerry Maguire references dated yet? Maybe I should ask GPT-3. Better yet, maybe I should train one from scratch using the dataset and model code that I’m sure has been made fully available to the open source community.
I’ll spoil the ending here: OpenAI has not made the code or dataset for GPT-3 available, instead opening a sign-up for API access to the model. GPT-2 had a staggered release of the model, citing concerns about malicious use of the model. Though the full GPT-2 was released in November, the dataset has not been released (but was reconstructed by others).
There’s been a lot of controversy around the decisions OpenAI has made. I’m definitely not equipped to handle a full discussion of the issues here. And they’ve been reported in detail in other venues. But what I will say is that it seems like a shame that all the components that made this model possible were open-source and the product isn’t. I’m not sure it matters a huge amount, since the vast talent pool in the community have managed to work around OpenAI’s decisions, for better or worse. But it seems like a shame that that effort has to be undertaken to replicate work, rather than build on it.
To summarize/conclude here: OpenAI researchers with their GPT work have continued to push the envelope on the potentials of language models and NLP more generally. There’s still a lot of work to do, especially around understanding what these models are actually learning and whether that learning could have potentially harmful downstream impacts.
In my next post, I’m going to spend a bit of time playing around with the GPT framework using HuggingFace’s awesome (and open-source) transformers library.