 Ben
Ben Kian Katanforoosh dives deep again in this episode, presenting inherent vulnerabilities in Neural Network architectures and how investigation into these vulnerabilities has spawned a whole new architecture known as Generative Adversarial Networks. Again, all of the materials come from the course unless otherwise noted.
Video No slides for this lecture, modules from Deeplearning.ai course
Adversarial examples
Kian starts off with the idea of an “adversarial attacks” as outlined in Szegedy (2014). In that paper, an adversarial example for a image classification NN is defined as “an imperceptible non-random perturbation to a test image” that changes the NN’s prediction.
So how do we find these adversarial examples? Harkening back to the art generation example in one of the previous lectures, remember that the objective was to apply a particular style to a particular image. Similarly, this “adversarial example” generation has the goal of creating an image that is not not class X, but is predicted as class X
In Kian’s example: Find an image that is not an iguana, but is classified as an iguana. In this case, the loss function cross-entropy, where the target prediction is iguana. Like with the art generation example, we keep iterating with an image, making changes to it until the iguana prediction is achieved.
Now, Kian asks, is this image likely to look like an iguana? The answer likely not. Kian shows the following visual to illustrate why:
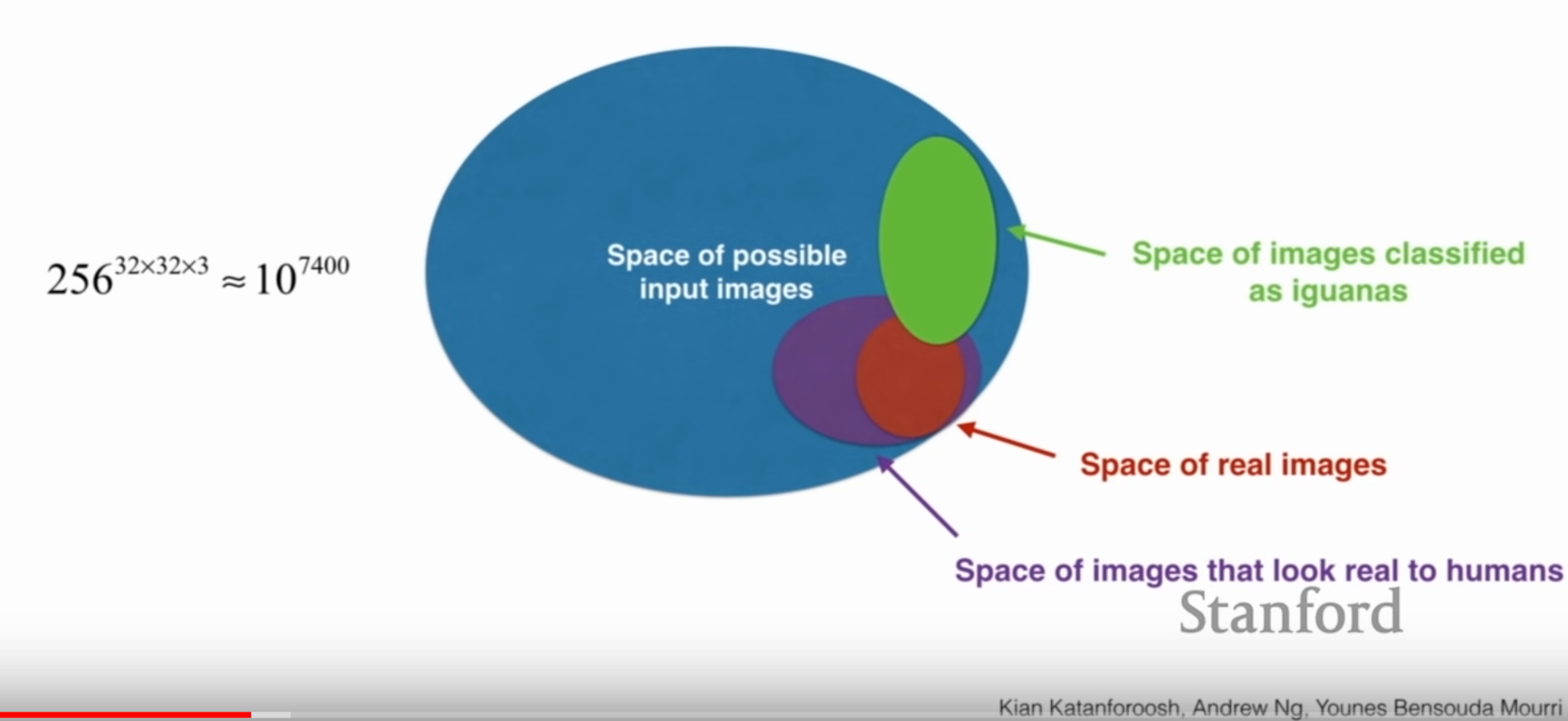
So our generated image falls into that green oval and only a small section of that oval is a real or real-looking image.
Now, to add complexity, what if we wanted an image that looks to a person like a cat, but is classified as an iguana? Again, we borrow from the art generation example, adding to the loss function that the image generated at the end of the process is close to an image of a cat. So not only does the prediction need to be iguana, the generated image needs to look like a cat.
So adversarial two ways there. This is a particularly pressing issue because it’s not particularly difficult to trick one of these image networks. And if that image network happens to govern access to some valuable information, a malicious agent could generate examples to gain that access.
Later in the lecture, Kian gives some insight as to why Neural Networks are susceptible to these examples. Particularly, he focuses on how the linear component of a NN may be to blame. More details are contained in Goodfellow (2015, but I’m going to try and summarize what I understand. Feel free to contact me if you want to discuss, my understanding is a bit fuzzy here.
The fact that neural nets tend to have a lot of linearity built in for the purposes of faster convergence means that it is fairly easy to find an adversarial example just by extracting the direction of the gradient of the loss function for each weight term. By constructing a version of x (the input) with its values tweaked just enough to cause an increase in loss for that observation, you can have a new input (x*) that is very similar to x but has a different prediction. You can imagine this problem gets worse with high dimensionality (as most neural networks have). There are basically endless directions to slightly tweak an input to generate a new input with a different prediction.
Now that Kian has demonstrated how easy it is to find an example to trick a NN, he goes into a potential line of defense: Generative Adversarial Networks (GANs). Just a note: Kian doesn’t say GANs are just for defense against adversarial attacks, but simply makes the point that the architecture are based on the idea that these attacks are possible.
Generative Adversarial Networks (GANs)
The idea behind GANs is to learn a representation of how the data is generated. The purpose of this is not only is the representation usually lower-dimensional, you can sample from that low-dimensional representation to generate new examples.
GANs actually involve two networks; a discriminator (D) and a generator (G). G tries to create observations that don’t exist in the data. D tries to identify whether an observation is real or generated.
The way training works for a GAN is that an image either from G or from the real data is passed to D. D makes a decision whether that image is real or generated.
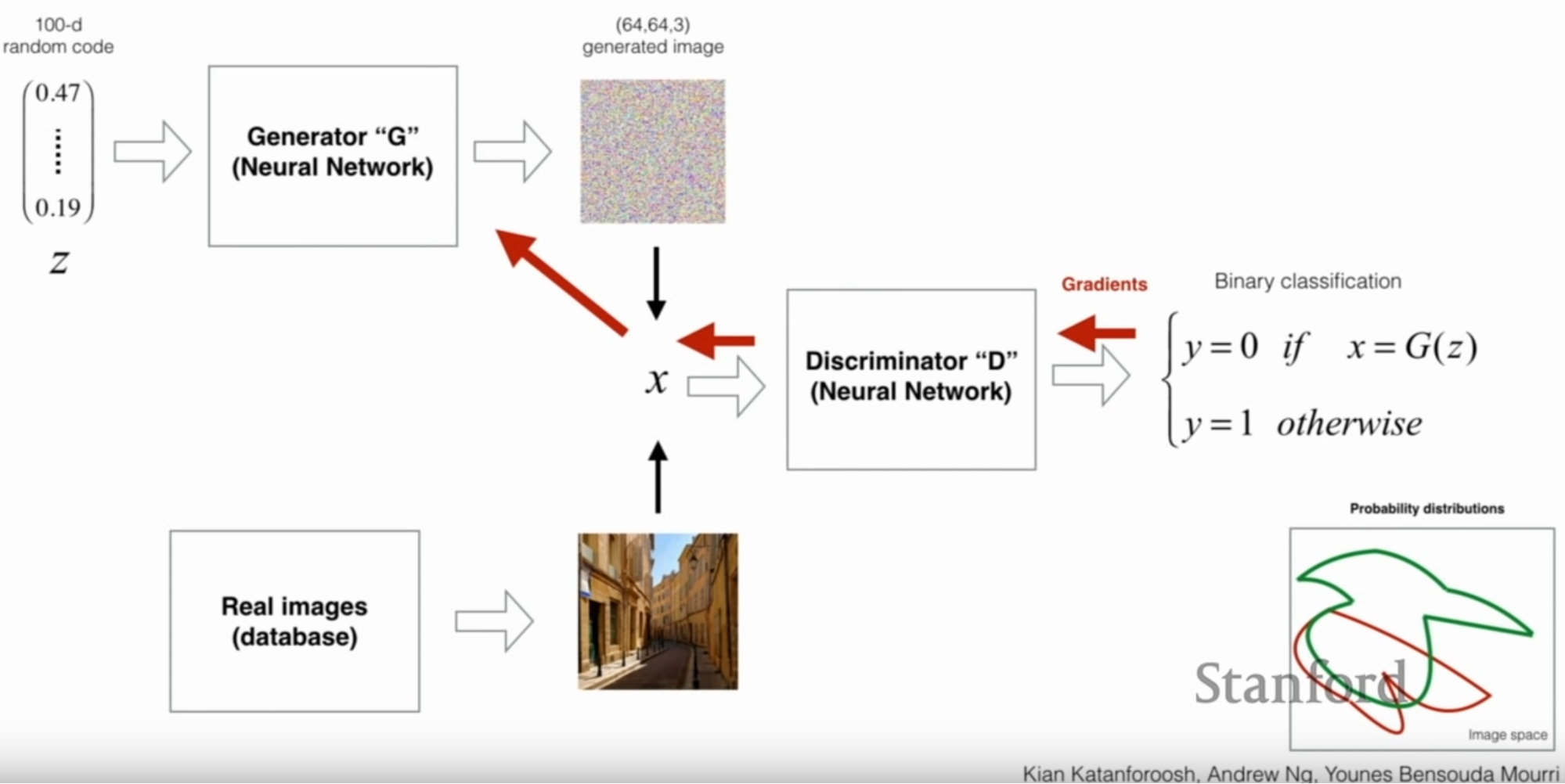
The loss function for D consists of two terms that push D to correctly identify real images as real and generated images as generated.

It would make logical sense that the loss function of G should just be the reverse of D’s. That is, D wants to correctly identify generated images and G wants to generate images that “fool” D into thinking they’re real. However, Kian points out that the reverse of D’s loss blows up (saturates) as D becomes more likely to be fooled. So a bit of math makes it so the function has a high gradient at the early stages of training (when D is likely to do better) and lower as D begins to be fooled. The below graphic should illustrate pretty well:
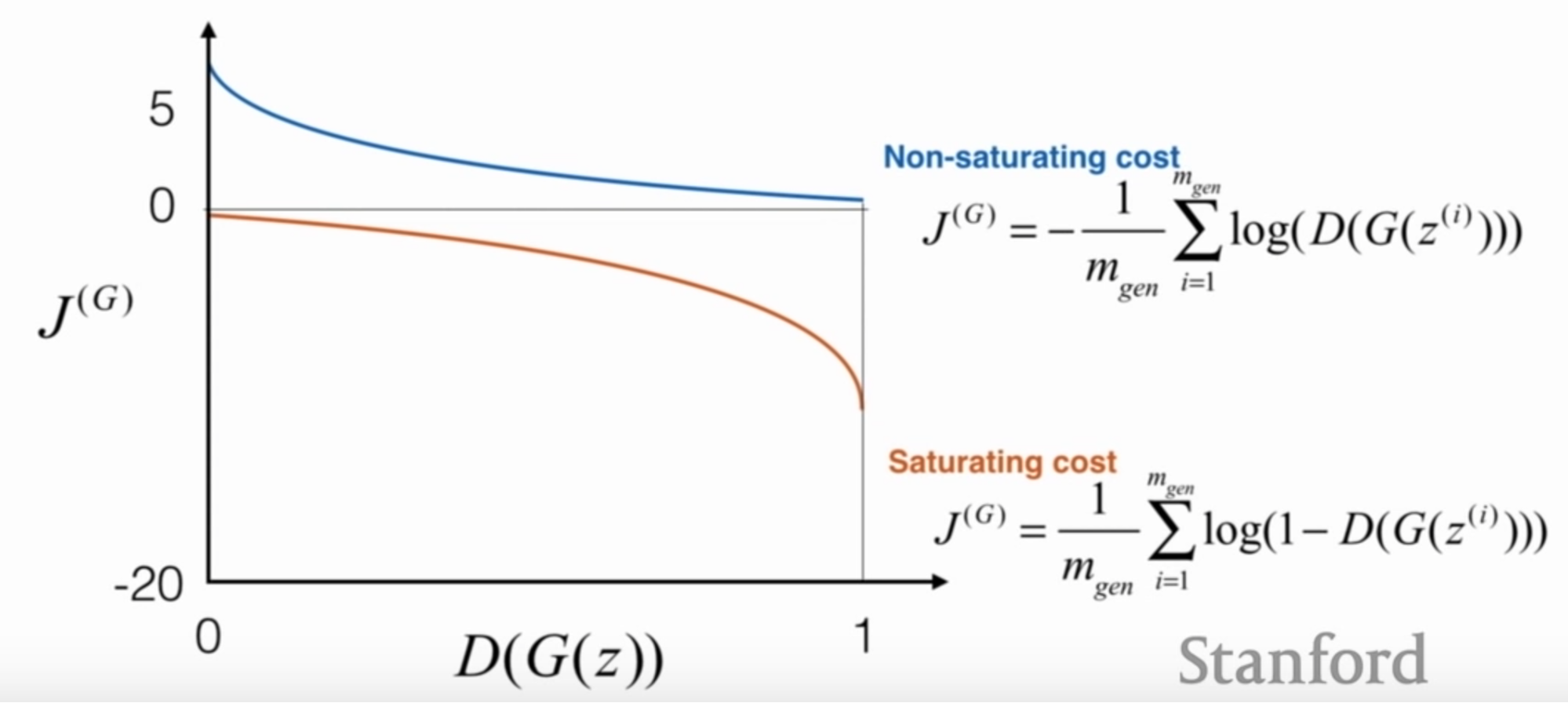
Kian ends the lecture with an example of the CycleGAN architecture, but I’ll leave that off since this post is already getting a bit saturated (ha ha!). That part of the lecture starts here.
What a lecture! Super dense this time and really interesting. I thought the bit about the linear vulnerabilities of NNs was very interesting, though I don’t fully understand it. It seems like it’s mainly an issue of the linearity allowing adversarial examples to be pretty easily derived. But I don’t see how a non-linear component guards against that. It seems like it wouldn’t be difficult to try a whole series of minor tweaks to get an adversarial example, regardless of the linearity of the components.
Open to discussing this more! Otherwise, see you next time!