 Ben
Ben It’s the last week! For as much as we covered, this all seems to have gone very fast. I have some reflections on the course I’ll dig into next week. This week, though, I’m releasing the week 7 notebook. In this week, we dug into some issues that face NLP work generally:
1) Assessing bias in language models and word embeddings 2) Conducting “fair” resesearch in the NLP context
In the first part of the notebook, we examine how information on what “group” a particular user belongs to can be informative for modelling, but can unfairly bias predictions for that group. The example I constructed used the movie review dataset from some of the previous assignments. I made up two groups:
- Picky users: 90% of their reviews would be negative
- Nice users: 50% of their reviews would be negative
Building a predictive model for identifying positive reviews is tricky here, because it can perform pretty well by just assigning any reviews from picky users to be negative and still achieve 90% accuracy in that group. But that means zero recall within that group. It won’t work to remove group entirely, since that’s a pretty useful indicator for whether a review is positive or not. But what if we assessed performance within group? Or, what if we somehow up-weighted the positive reviews among the picky users?
The next section digs into identifying bias in word embeddings. There’s been a fair amount of research into how word embeddings encode a lot of racial and gender bias into their representations. Garg et. al. (2018) presented some very powerful visualizations of this bias:
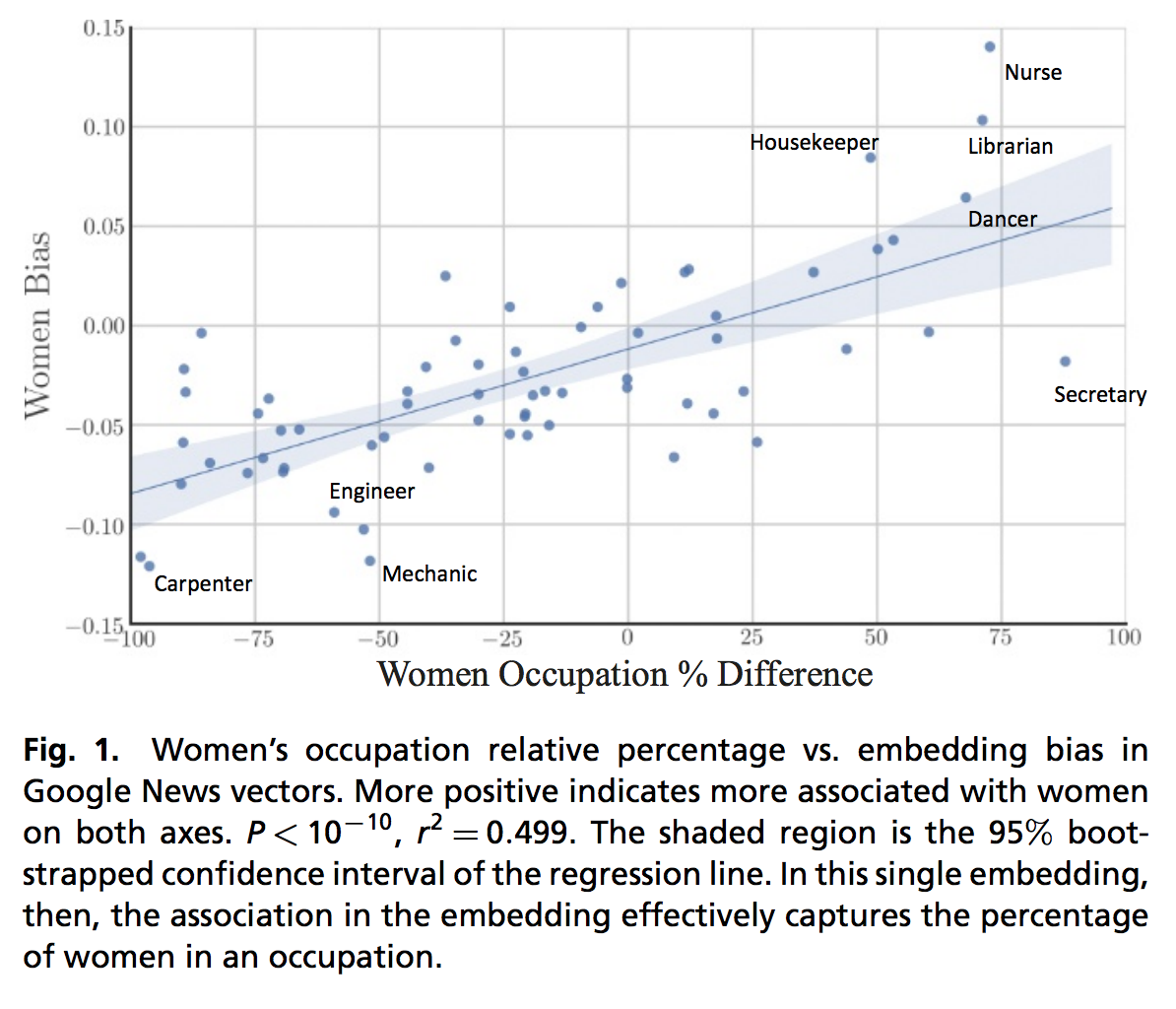
On the Y axis is the difference between the similarities of individual words to female words vs male words. So more positive = stronger association with women, more negative = stronger association with men. It’s compared, then, to the occupation difference by gender. You can see pretty clearly that traditionally female occupations have stronger association with women.
As mentioned above, this is a strong signal that might be useful in some contexts. But there’s nothing intrinsically female about nurses and nothing intrinsically male about engineers. So it makes sense to be aware that these biases are part of the representations if used as-is. And, if used for the purpose of making “unbiased” decisions, they will create problems.
The example in the notebook attempts something similar to Garg et. al. (2018), creating a visualization of particular words association with a “gender” vector. This just shows how simple it is to pick out this bias. Debiasing, on the other hand…is a bit more complicated.